
Deep Multi-Module Based Language Priors Mitigation Model for Visual Question Answering
2023-12-28 09:12:10YUShoujian于守健JINXueqin金學(xué)勤WUGuowen吳國(guó)文SHIXiujin石秀金ZHANGHong
YU Shoujian(于守健), JIN Xueqin(金學(xué)勤), WU Guowen(吳國(guó)文), SHI Xiujin(石秀金), ZHANG Hong(張 紅)
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract:The original intention of visual question answering(VQA) models is to infer the answer based on the relevant information of the question text in the visual image, but many VQA models often yield answers that are biased by some prior knowledge, especially the language priors. This paper proposes a mitigation model called language priors mitigation-VQA (LPM-VQA) for the language priors problem in VQA model, which divides language priors into positive and negative language priors. Different network branches are used to capture and process the different priors to achieve the purpose of mitigating language priors. A dynamically-changing language prior feedback objective function is designed with the intermediate results of some modules in the VQA model. The weight of the loss value for each answer is dynamically set according to the strength of its language priors to balance its proportion in the total VQA loss to further mitigate the language priors. This model does not depend on the baseline VQA architectures and can be configured like a plug-in to improve the performance of the model over most existing VQA models. The experimental results show that the proposed model is general and effective, achieving state-of-the-art accuracy in the VQA-CP v2 dataset.
Key words:visual question answering (VQA); language priors; natural language processing; multimodal fusion; computer vision
0 Introduction
With the advent of the information age, people’s access to information has become more diversified. Simple text is no longer enough to meet people’s demand for information, and pictures have become one of the main channels to obtain information. Images contain a wealth of visual information[1]including obvious information such as relative positions, colors, quantities, shapes and sizes, as well as inferential information such as time, places, events,etc., which cannot be fully summarized by simple text. Images are also easy to access, save and understand, which makes them a quality channel for people to access everyday information. Therefore, in the environment of information explosion, how to extract the needed knowledge from a large amount of image information becomes an urgent problem. At the same time, in the era where artificial intelligence continues to move forward, a large number of human-computer interaction technologies[2]are flourishing, with plenty of results emerging both in industry and in everyday life. Most of the bots like question-and-answer systems or some physical robots, are still at the stage of text or voice conversation[3]and lack the ability to utilize visual information that can be found everywhere in life. These so-called artificial intelligence products cannot achieve true responses to these needs without the ability to understand, filter and reason about images. In response to these needs, visual question answering (VQA) has emerged as the basic module that underpins many cutting-edge interactive intelligence systems.
VQA combines advanced technologies from two disciplines: computer vision and natural language processing[4]. It needs to process both textual and image information, reason the answer in the image for the textual question, and answer in natural language. It is a neural network that takes the natural language text and visual images as the input and the natural language text as the output. An interactive form is used to find answers in the provided images in response to the questions asked by people. The process is accompanied by advanced techniques for encoding visual[5]and textual[6]information, feature extraction, feature fusion, cross-modal inference,etc., and has important theoretical research value.
VQA has a wide range of application scenarios. It can help people with visual perception impairment to more easily understand various picture information in the online environment, identify the objects around them and understand their surroundings, and is a powerful and reliable channel for providing information[7]. For intelligent dialogue systems, it is desired that they simulate human conversations including some interactions about images. VQA further fills the gap of intelligent dialogue systems in image understanding by extracting information from both images and texts, enhancing the understanding of dialogue systems and bringing them closer to the human level. For search engine optimization, the role of simple text search is limited. The research on VQA can further improve the search accuracy so that it cannot only search by single image or single text but also by combined images and texts. VQA can also be further applied to various fields such as early education, intelligent driving, medical quizzes,etc.
1 Related Work
1.1 Language priors in VQA
Existing VQA systems generally suffer from language priors[8]. VQA is a question-answering system based on language text and visual images, which obtains answers by understanding the input question text and reasoning over image information. The VQA can be divided into three main parts: natural language processing, image feature extraction and multimodal fusion reasoning[9]. The model training in these parts inevitably leads to the answers influenced by this prior knowledge because of some biases existing in the dataset, resulting in language priors problems.
The main sources of information for reasoning about answers to VQA can be briefly summarized as visual information combined with textual information, single visual information[10]and single textual information. A valid reasoning process should combine both visual and textual information to obtain an answer, while an answer obtained by reasoning from only a single piece of information is considered to have some kind of prior knowledge[11]. The effect of reasoning about the answer from the question text alone is called a language prior problem. The problem with language priors in VQA is that the model is more likely to answer the more common answers in an answer base without reasoning about what the real information in the picture is. For example, most of the answers in the answer base for apple color may be red, with only a low percentage being green. When the text of the question is “What color is an apple?”, the model is more likely to arrive at the answer “red” based on the most common answer in the answer base, even if the incoming image is a green apple. On the VQA 1.0 dataset, an accuracy of 41% was obtained by answering “tennis” for the sports-related questions, and “Yes” to the question “Did you see...” gives an accuracy of about 87%[12].
1.2 Current status of research
The existing approaches to dealing with language priors can be briefly divided into three types.
The first one is to use additional annotations and an external knowledge base to reduce the language priors. Most commonly, additional image and text annotations are used to improve the baseline ability of visual reasoning[13]. At the same time, the knowledge that can be acquired from visual images is limited[14], and some of the advanced knowledge may need to be acquired by external means such as knowledge bases. For example, for the question “Is there a fruit in the picture?”, a VQA model needs to know what a fruit is before it can answer a similar question. Heoetal.[15]proposed a model called hypergraph transformer that constructed a question hypergraph and a query-aware knowledge hypergraph and inferred an answer by encoding inter-associations between two hypergraphs and intra-associations in both hypergraphs themselves. However, finding a scalable framework to adaptively select the required knowledge from the knowledge base is an urgent challenge.
The second approach is data augmentation. This approach usually generates counterfactual training samples to balance the training data. For example, for the question “What color is an apple?", the answer in the training data may be “yellow”, “green”, “pink”, “red” and so on. These answers may not match reality but can force the model to learn the differences in features in the image, rather than making conclusions based on the distribution of questions and answers. This approach has a greater advantage over other de-biasing methods on the VQA-CP[8]dataset, but making a completely balanced dataset is difficult and takes a lot of manpower. For example, Gokhaleetal.[16]improved out-of-distribution generalization by exposing the model to different input variants,i.e., changing the targets in the image or problem to force the network to learn the change in the image or problem. It is essentially a data augmentation that strengthens the ability to reason about the problem in conjunction with the image by changing the targets of the image, thus weakening the language priors.
The third approach is to use an additional network module[17]. Sietal.[18]added a network module to check each answer of the generated candidate answer set. The check is done by merging the questions and answers with the images into the pre-trained model for a visual implication task. The candidate answer sets are re-ranked based on the checking results, and the answer with the highest score is the output. A more common approach is to remove all the priors by training a separate network module with the input as the question text and the output as the answer, penalizing examples that can be answered without looking at the images. For example, Niuetal.[19]reduced the effect of language priors by creating a separate linguistic and visual branch to detect language and visual priors and subtracting direct linguistic effects from the total causal effects[20].
2 Approach
2.1 Processing of language priors
Among the existing models for handling language priors mentioned in section 1, the first two types of approaches require significant labor costs and do not address the root cause of the problem. In this paper, we mainly consider the case of dealing with language priors by adding additional network models. Most of the existing papers consider the language prior as a bad influence and wish to remove the entire language priors. The study in this paper argues that this approach is too absolute and that the language priors obtained through the problem text can be divided into positive and negative language priors so that different language priors can be captured and handled in different cases. Negative language priors refer to specific answers derived from the model based on the question text corresponding to the most common answers in the answer database. For example, the answer to “What color is an apple?” is mostly “red” or “green”, so the model directly derives the answer without reasoning in the image information. We choose to remove such negative language priors. Positive language priors are mainly those in which the model can accurately range the answers based on some knowledge of the question text. The model determines the type of answer based on the type of question in the question text, thus further narrowing the range of candidate answers. When answering the question “What is the color of an apple?” the answer space can be narrowed down to the range of colors, making the answer more precise. For positive language priors, we choose to keep them.
2.2 Causal graph in VQA
The main sources of information for reasoning about answers in VQA can be briefly summarized as obtaining through visual information combined with textual information, single visual information and single textual information, as shown in Fig.1, where Q, V, A and F denote the question text, visual images, answers and features of the question text and visual images, respectively; g and b repesent positive effect and negative effect, respectively; × means removal.
From this, further inferences can be made about the causality of VQA[21]. The constrained random variables are represented by capital letters (e.g.,Vfor a picture containing information), and the observations are represented by lowercase letters (e.g.,vfor a specific picture). WhenV=v(vis a picture containing information,e.g., a picture with red apples) andQ=q(qis the text of a question aboutv,e.g., “What color are the apples?”), the score for answerA=a(the answer to the question text based on the content of the picture,e.g., “red”) is calculated by
Yv, q(a)=Y(V=v,Q=q).
(1)
As shown in Fig.1(a), macroscopically it is the three paths that jointly influence the generation of answerA. Therefore, the formula to further represent the answer obtained by VQA is
Yv, q(a)=H(V=v,Q=q,F=fv, q),
(2)
whereFis the influence factor of the visual image and question text after multimodal fusion[22].
The formula for the total effectETat the macro level is
(3)
where*denotes information that has not undergone multimodal fusion (e.g.,v*is the information that has not undergone multimodal fusion).
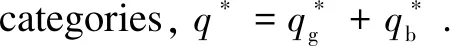
(4)
Therefore removing the negative language prior can be regarded as finding the total indirect effectETI, it is defined as
ETI=ET-END=Hv, q, f-Hv*, q-qg, f*.
(5)
The total indirect effect can be maximized during the training of the model.
2.3 Language prior mitigation (LPM)-VQA
The research in this paper proposes the LPM-VQA model, which mitigates language priors in two main ways. On the one hand, two network modules are added to retain positive language priors and remove negative language priors. The input of one network model is the question text. The weights of the corresponding answers are removed from the set of answer candidates in the VQA model. The other network model has the question category as the input, and the corresponding answer’s weight is added to the answer candidate set of the VQA model if the answer category corresponding to the question is obtained. On the other hand, the language prior is further mitigated by designing a new loss function to balance the loss weights of each answer corresponding to the questions of VQA. Finally, the set of candidate answers is reordered to obtain the candidate answer with the highest score as the output. The overall network structure of the model LPM-VQA is shown in Fig.2.
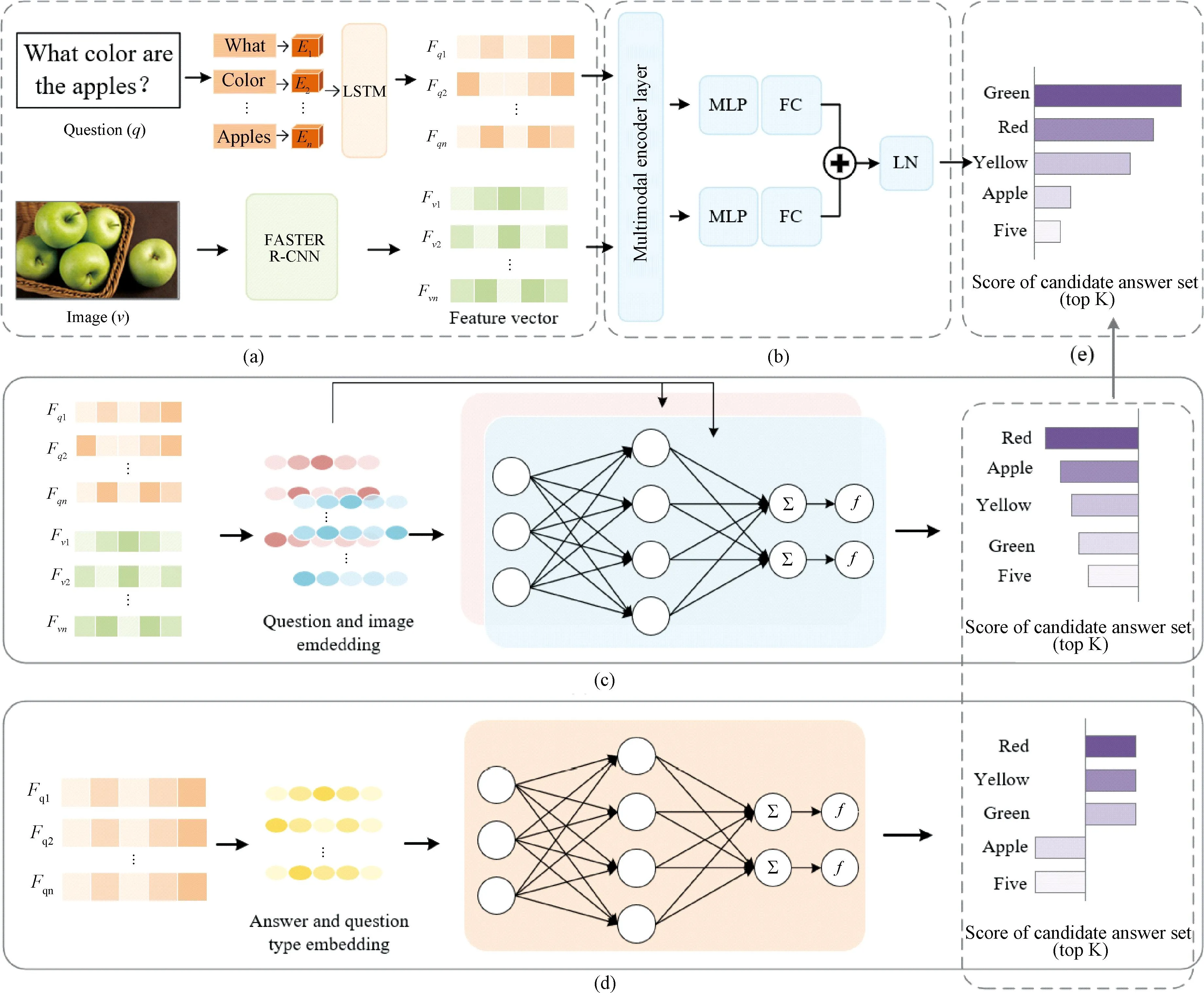
Fig.2 LPM-VQA architecture: (a)feature extraction module; (b)multimodal fusion reasoning module; (c) negative prior module; (d) positive prior module; (e) answer rearrangement module
The LPM-VQA model is divided into five main parts. The first part is shown in Fig.2 (a), where the deep featuresFvandFqof the input imagevand the question textqare obtained by a neural network. The LPM-VQA network selects faster regionconvolutional neural networks(Faster R-CNN)[23]to do deep feature extraction on the visual imagev. It is based on VGG16[24]network to extract the image features and get the feature map after downsampling. It also goes through region proposal network(RPN) to automatically generate the candidate detection frames and classify and fine-tune the detection frames. Here we do not need to get the actual result of object detection, but use its intermediate resultFv, the deep feature representation of the image. For the question textqof the image, all questions are first lower-cased, and punctuation is removed. Then the text is preprocessed and encoded to obtain a vectorized representation of the input text. After that, the long short-term memory (LSTM)network[25]is used to extract the deep features of the textFq.
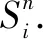
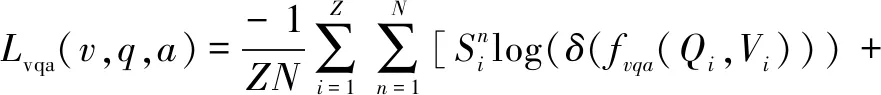
(6)
The third and fourth parts are shown in Figs.2(c) and 2(d), respectively, and are the main parts of the model to mitigate the language priors. As shown in Fig.2(c), the main function of the neural network in the negative prior branch is to remove the parts of the language priors that are not reasonable. That is to say that the answers can be derived by reasoning about the problem text alone without combining images. Based on this feature the vector representation of the question text in the deep features in the first part is extracted as input and passed into an MLP for answer prediction to obtain the answer set scoreSqnk(wherekis the size of the candidate answer set). The same structure of the network is also used to remove visual priors,i.e., answers that can be derived by reasoning about the images alone without combining the question text. Based on this feature the vector representation of the visual image in the deep feature in the first part is extracted as input and passed into the MLP for answer prediction to obtain the answer set scoreSvk.Ais the answer prediction space and contains thousands of candidate answers. Then the final resulting candidate answer set scores can be expressed as
Sqnk=topK(argsort(fqn(Qi))),
(7)
Svk=topK(argsort(fv(Vi))).
(8)
As shown in Fig.2(d), the main function of the neural network with positive prior branching is to retain the part of the language prior knowledge that facilitates answer pushing. That is, the type of answer is determined based on the type of questions, thus narrowing down the range of answers. According to this feature, the vector representation of the question text type in the deep features in the first part is extracted as the input and passed into the MLP for answer prediction to obtain the answer set scoreSqpk(wherekis the size of the candidate answer set). It can be expressed as
Sqpk=topK(argsort(fqp(Qi))).
(9)
The fifth part is shown in Fig.2(e). The candidate set distribution of each module is fused by the functionGto determine the final scoreSvqakof the candidate answer set. It is defined as
Svqak=G(topK(argsort(fvqa(Qi,Vi))),Sqnk,Svk,Sqpk).
(10)
The answer with the highest score among them is taken as the final answer, as shown in Fig.3.

Fig.3 Algorithm flow chart of fusion-based model
Based on the formula and the branches, the final cross-entropy loss function can be derived as
L=k1Lvqa(v,q,a)+k2Lva(v,a)+k3Lqp(q,a)+k4Lqn(q,a).
(11)
2.4 VQA objective function
In section 2.3,language priors are mitigated by adding the module indepent of any baseline VQA architectures. It is similar to a plugin that can be placed on any of the baseline VQA models but essentially does not have a performance improvement on the baseline VQA model itself. We can use some intermediate results of the added module to optimize the performance of the baseline VQA model. The language priors problem arises because the real world tends to have certain regularities, like apples tend to be red, soccer balls tend to be round, and so on. Thus answers about real-world images have the property of long-tail distribution. This property leads models to achieve high accuracy by prior knowledge alone, without reasoning based on the images associated with the questions provided. Therefore we can dynamically compute the loss weights according to the strength of the language priors. Thus, the proportion of the loss value of each answer in the total loss is balanced to mitigate the language priors.
Theoretically, we can dynamically assign a loss weightWto each answer based on the strength of the language priorsα(0<α<1)). The larger the value ofα, the stronger the language priors. The strength of the language priors for an answer can be calculated based on its probability of arriving at the correct answer when only the question is entered.So it can be expressed based on the intermediate results in the added negative prior branch as
(12)
When the answerAiderived from the negative language priors branch is the correct answer,αiis larger, and the corresponding loss should be smaller at this time,i.e., the corresponding loss value weightWishould be smaller. And when the answerAiderived from the negative language priors branch is the wrong answer,αiis smaller, and the corresponding loss should be larger at that time,i.e., the corresponding loss value weightWishould be larger. Further, we can derive the weights of the language priors corresponding to each answer as
Wi=(1-αi)β,β≥0,
(13)
whereβis the hyperparameter, the larger the value ofβ, the smaller the weightWiof the language priors corresponding to the answer.
Combined with the loss weightWiof the answerAi, the loss function of the baseline VQA model can be updated as
(14)
Based on the formula and the branches, the final cross-entropy loss function can be derived as
L=k1Lvqa_ls(v,q,a)+k2Lva(v,a)+k3Lqp(q,a)+k4Lqn(q,a).
(15)
3 Experiments
3.1 Datasets
The experiments in this paper are mainly based on the VQAv2 and VQA-CPv2 datasets. Among them, the VQAv2 dataset is one of the most commonly used datasets in VQA, with more balanced question types and images corresponding to the questions than VQAv1. It contains 205 k images from real scenes, 1.1 M question text related to images, and 6.6 M human annotations related to images. One image corresponds to about five questions,one question corresponds to about ten answers, and the test sets are not annotated. With the help of the VQAv2 dataset, it is possible to verify that the addition of modules for model mitigation of language priors does not affect the results of the baseline VQA model.
The VQA-CPv2 dataset is characterized by a significantly different distribution of answers to the questions in the training and test sets. Models that rely excessively on prior knowledge perform worse in the test set. The VQA-CPv2 training set consists of 121 k images from real scenes, 438 k image-related questions, and 4.4 M corresponding answers. The test set consists of 98 k images from real scenes, 220 k image-related questions, and 22 M corresponding answers. It facilitates us to test the model’s ability to mitigate the language priors.
3.2 Implementation details
The experiments in this paper are based on three baseline VQA networks: stacked attention network (SAN)[29], bottom-up and top-down attention network (UpDn)[30], and simplified multimodal relational network (S-MRL)[31]. The Faster R-CNN framework is used for deep feature extraction of the images. The top-kregion was chosen for each image, where the value ofkwas fixed at 36. To process the question text, we lowercase questions and remove punctuation. The final embedding size was set to 4 800.
The visual language branch uses a simplified multimodal relational network (MuRel)[31], which consists of a bilinear fusion module between the image and the problem representation for each region, and an MLP consisting of three fully connected layers. These layers have the rectified linear unit(ReLU) activations of sizes 2 048, 2 048 and 3 000. The negative language prior branch consists of a problem representation and a pure problem classifier. The problem classifier is implemented by an MLP that has three fully connected layers with ReLU activation. This MLP has the same structure as the visual language branch classifier with different parameters. The negative visual prior branch consists of a problem representation and a pure visual classifier. The pure visual classifier has the same structure as the pure language classifier, but different parameters. The positive language prior branch consists of a representation of the problem type and a pure problem classifier.
All experiments are conducted with the Adam optimizer. According to the accuracy curves on the training and validation sets in Fig.4, 26 epochs were used. In the first 7 epochs, the learning rate increased linearly from 1.5×10-4to 6.0×10-4, and decayed by 0.55 every two epochs after 14 epochs. The batch size is set to 256.
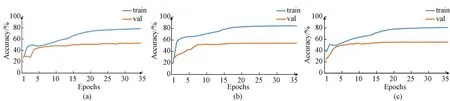
Fig.4 Accuracy of LPM based on different baseline VQA models on the VQA-CPv2 training and test sets: (a) SAN; (b) UpDn; (c) S-MRL
3.3 Quantitative results
Table 1 presents the results of the proposed LPM-VQA and other advanced methods on the VQA-CPv2 dataset. These methods can be roughly classified into the following categories: (i) methods that modify the linguistic module, decouple the linguistic concepts via decomposed linguistic representations(DLR)[32]or generate visually-grounded question representations with visually-grounded question encoder (VGQE)[33]; (ii) methods that use human vision or text interpretation to enhance visual attention, including human importance-aware network tuning (HINT)[34]and self-critical reasoning(SCR)[13]; (iii) methods that capture language priors directly with separate branching models, such as reducing unimodal biases (RUBi)[35]and learned-mixin+H (LMH)[36].
In Table 1, the results with higher accuracy without additional generation of training samples are bolded, and the results with the best accuracy in each column are highlighted with underlines.The average accuracy of LPM is obtained over 5 experiments using different random seeds.As can be seen from Table 1, LPM obtains optimal performance among currently available models that do not generate additional training samples based on the VQA-CPv2 dataset. Among them, the S-MRL-based LPM model achieves 55.26% of the optimal results, which is 3.25% higher than that of the existing optimal model. Meanwhile, better performance was achieved on different model-based constructs, demonstrating the generalizability of the model debiasing ability, with 18.16%, 16.49% and 17.96% improvement of the accuracy compared to the base model, respectively. The improvement is particularly evident in the “Yes/No” type problems, which is 18% higher than that of LMH of the optimal model in these problems.
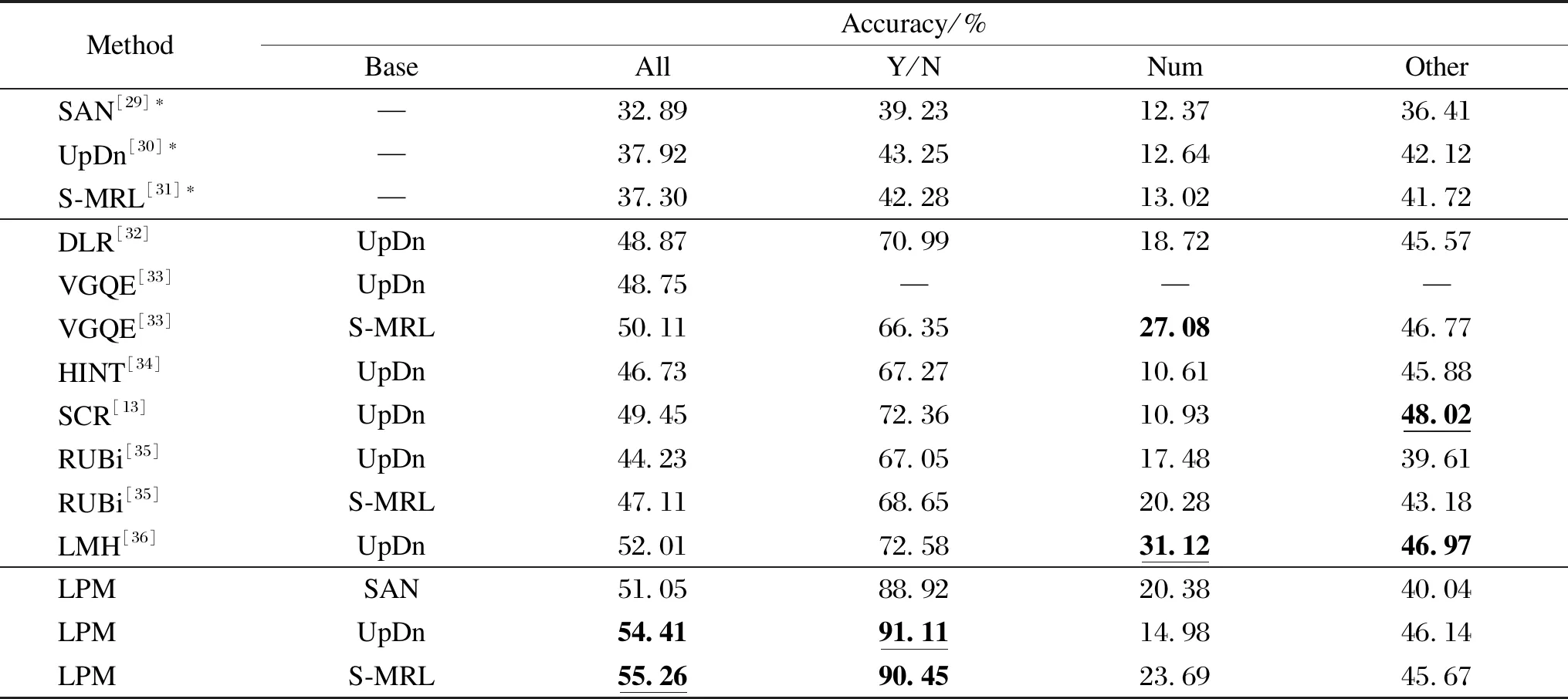
Table 1 Accuracy of the model on the VQA-CPv2 test set
The accuracy of models on the VQAv2 test set is shown in Table 2. As can be seen from Table 2, the proposed model LPM obtains superior performance among currently available models that do not generate additional training samples based on the VQAv2 dataset. It proves that the proposed model for mitigating language priors does not affect the results of the baseline VQA model. It can be observed that all types of models for mitigating the language priors affect the results on the VQAv2 dataset to some extent. This is because the correction for the language priors problem have been done so that the certain prior factors that can influnce the accuracy of the answers are lost in the datasets with severe language prior problems (i.e., datasets in which the answer distribution of the questions at training is approximately the same as that at testing). As a result, the answers are obtained by relying entirely on the joint inference ability of the model.The proposed model is slightly improved on the UpDn[30]base model, while the accuracy is slightly reduced on both SMR-L[31]and SAN[29]base models, which may be caused by overcorrecting the language priors.
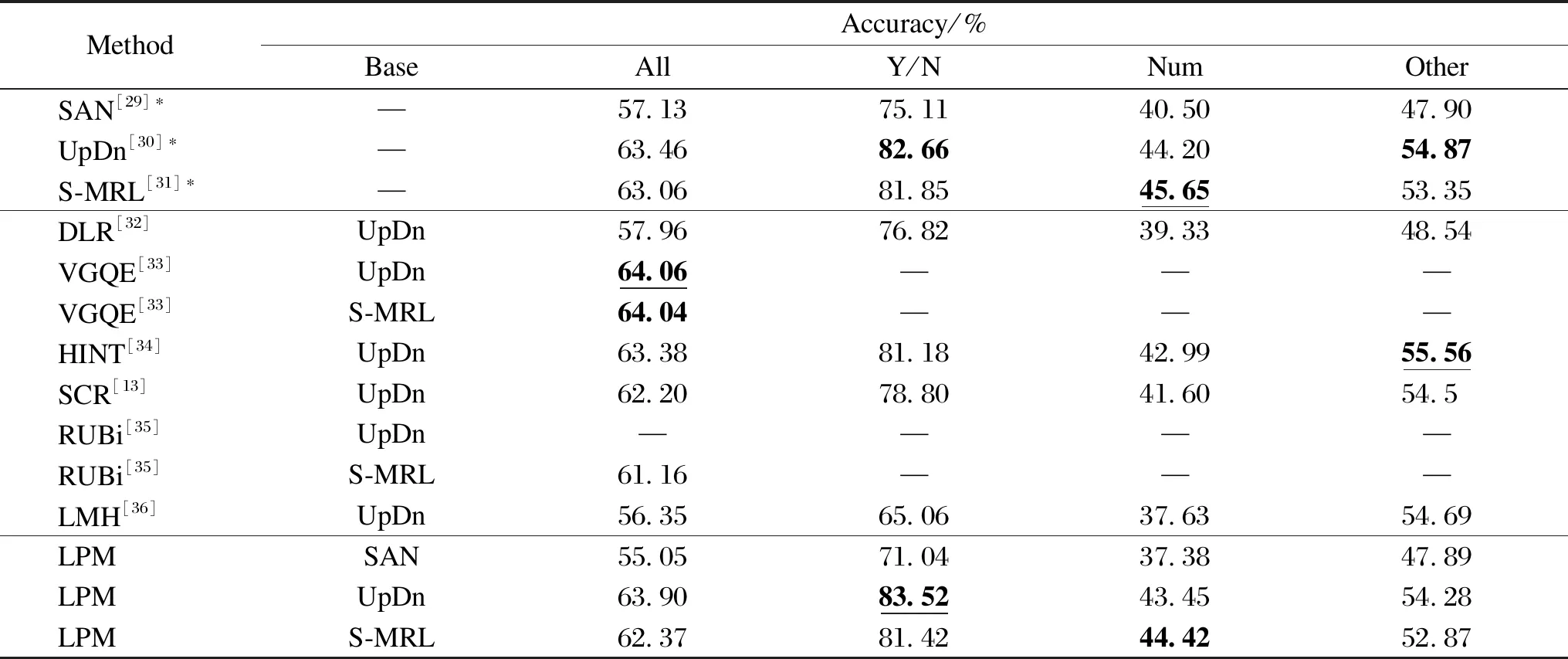
Table 2 Accuracy of the model on the VQAv2 test set
To test the effectiveness of our designed dynamic loss function, we used the loss function without dynamic weights,i.e., Eq. (11) for the ablation experiments, as shown in Table 3.The accuracy of LPM models based on the three baselines of SAN, UpDn and S-MRL is improved by 0.73%, 0.32% and 0.08%, respectively. The results demonstrate that our redesigned loss function by dynamically assigning loss weights to each answer can improve the accuracy of the VQA network.
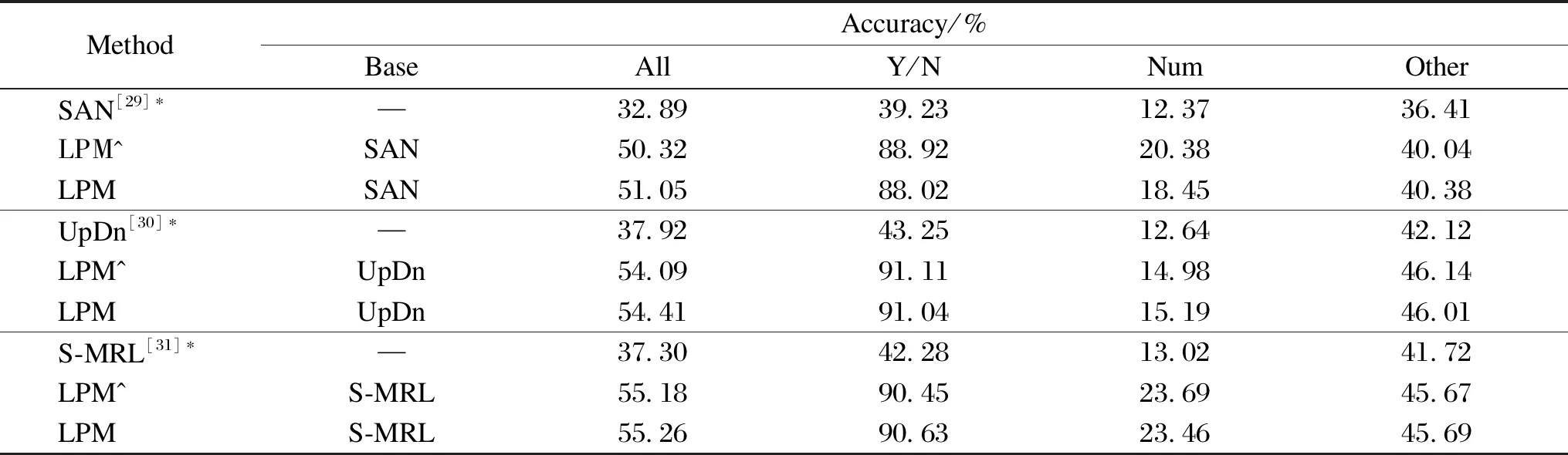
Table 3 Accuracy of the model on the VQA-CPv2 test set based on different loss functions
There are many kinds of questions in the dataset, and each question is answered with different levels of difficulty[37]. We selected some targeted questions to test their accuracy. As can be seen from Table 4, the proposed model has a significant improvement in accuracy for some of the question types where there is an exact range of answers,e.g., the answer to the question “What color” can be determined in the color range, so the accuracy of the LPM model based on the three baselines of SAN, UpDn and SMRL is improved by 18.04%,7.10% and 12.47%, respectively. That is because we remove the negative language priors while retaining the positive ones.
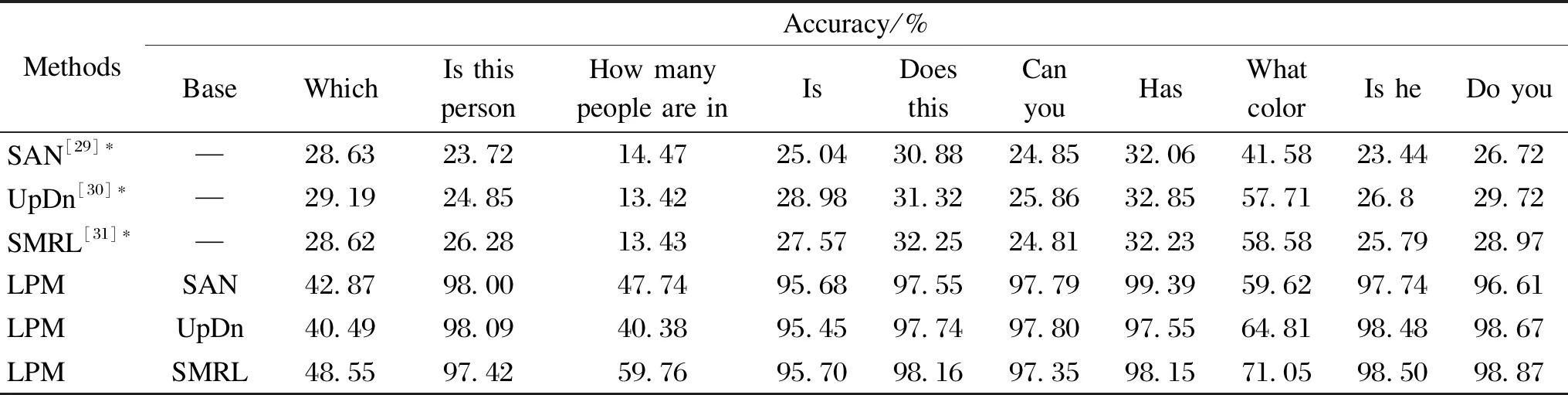
Table 4 Accuracy of the model on the VQA-CPv2 test set based on different problem types
3.4 Qualitative Results
The qualitative results verify that the proposed LPM model is effective in reducing linguistic bias while preserving linguistic context. Figure 5 shows the qualitative comparison of VQA-CPv2 dataset, where the brown bold answer denotes the ground-truth one. As shown in the second row of Fig.5, for the question “What animals are in the picture?”, the LPM model yields the highest score of “cow”. It is obvious that it combines the information of the horse in the picture. Because the pattern of the horse looks more like a cow, the wrong decision is made, demonstrating the LPM’s ability to reason with images. As shown in the third row of Fig.5, both the S-MRL and UpDn models are biased towards giving tennis-related answers for sports-type questions, and the LPM model successfully mitigates the prior. For example, for the question “Where is the man in the picture?”, the LPM model gives the highest score as “playground”, which may not be the optimal answer, but it fits the information in the picture and cannot be considered as completely wrong. Moreover, the score of the answer about tennis balls in this reasoning is lower than that of the S-MRL and UpDn models. As shown in the fourth row of Fig.5, the LPM model preserves the context of the question while mitigating the language prior. For the “yes/no” category, the LPM model gives only “yes” or “no” answers, while all other answers have zero scores. For the “number” question, the LPM model also gives only numeric answers, while the S-MRL and UpDn models, gives some non-numeric answers due to the interference of other information in the picture.
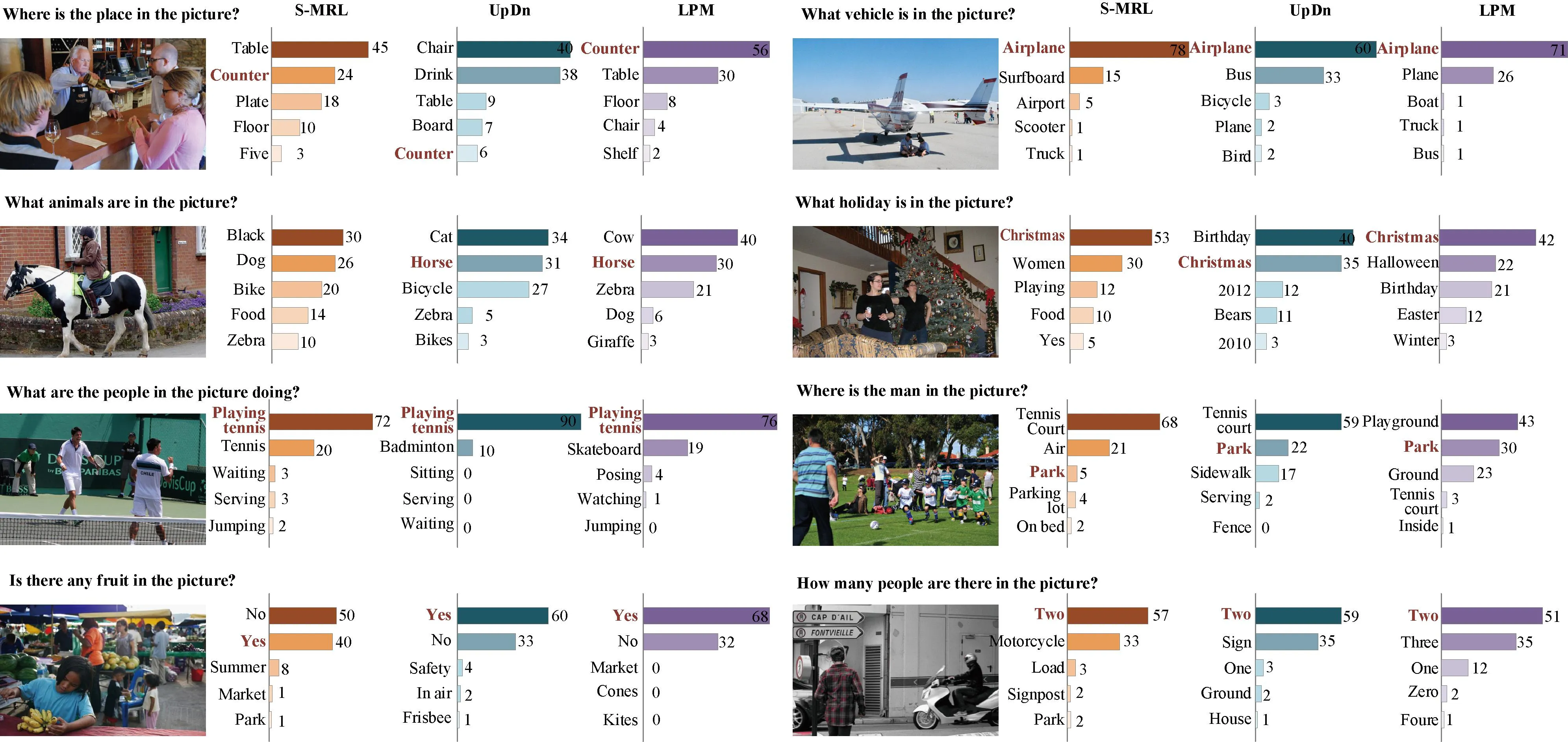
Fig.5 Qualitative comparison of VQA-CPv2 dataset
4 Conclusions
In this paper, we propose a mitigation model LPM-VQA for the language priors in VQA. The model classifies language priors into positive and negative language priors and uses different network branches for different cases to capture and process them. A loss function is also proposed, which can further mitigate the language priors by dynamically assigning loss weights to the loss values of each answer according to the strength of the language priors. In addition, it is a general framework that can be easily combined with existing VQA models and further improve performance. The experimental results demonstrate the generality and effectiveness of LPM-VQA.
猜你喜歡
四川大學(xué)學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2025年1期)2025-02-08 00:00:00
四川大學(xué)學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2024年5期)2024-01-01 00:00:00
知音(月末版)(2023年3期)2023-06-30 16:03:26
Journal of Donghua University(English Edition)(2022年3期)2022-08-08 05:47:38
Acta Mathematica Scientia(English Series)(2021年5期)2021-10-28 05:43:56
山東理工大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2021年5期)2021-09-23 01:11:24
書香兩岸(2020年3期)2020-06-29 12:33:45
環(huán)球時(shí)報(bào)(2019-03-25)2019-03-25 10:55:34
天津詩(shī)人(2017年1期)2017-05-07 03:23:47
江西畫報(bào)(2013年6期)2013-04-29 00:44:03
 Journal of Donghua University(English Edition)2023年6期
Journal of Donghua University(English Edition)2023年6期
- Journal of Donghua University(English Edition)的其它文章
- Recent Progress on Fabrication of Thermal Conductive Aluminum Nitride Fibers
- Cleaning of Multi-Source Uncertain Time Series Data Based on PageRank
- Detection of Residual Yarn in Bobbin Based on Odd Partial Gabor Filter and Multi-Color Space Hierarchical Clustering
- Electromagnetic and Thermal Characteristics of Molybdenite Concentrate in Microwave Field
- Path Planning of UAV by Combing Improved Ant Colony System and Dynamic Window Algorithm
- Robot Positioning Based on Multiple Quick Response Code Landmarks