
A Weakly-Supervised Crowd Density Estimation Method Based on Two-Stage Linear Feature Calibration
2024-04-15 09:37:16YongChaoLiRuiShengJiaYingXiangHuandHongMeiSun
Yong-Chao Li , Rui-Sheng Jia , Ying-Xiang Hu , and Hong-Mei Sun
Abstract—In a crowd density estimation dataset, the annotation of crowd locations is an extremely laborious task, and they are not taken into the evaluation metrics.In this paper, we aim to reduce the annotation cost of crowd datasets, and propose a crowd density estimation method based on weakly-supervised learning, in the absence of crowd position supervision information, which directly reduces the number of crowds by using the number of pedestrians in the image as the supervised information.For this purpose, we design a new training method, which exploits the correlation between global and local image features by incremental learning to train the network.Specifically, we design a parent-child network (PC-Net) focusing on the global and local image respectively, and propose a linear feature calibration structure to train the PC-Net simultaneously, and the child network learns feature transfer factors and feature bias weights, and uses the transfer factors and bias weights to linearly feature calibrate the features extracted from the Parent network,to improve the convergence of the network by using local features hidden in the crowd images.In addition, we use the pyramid vision transformer as the backbone of the PC-Net to extract crowd features at different levels, and design a global-local feature loss function (L2).We combine it with a crowd counting loss(LC) to enhance the sensitivity of the network to crowd features during the training process, which effectively improves the accuracy of crowd density estimation.The experimental results show that the PC-Net significantly reduces the gap between fullysupervised and weakly-supervised crowd density estimation, and outperforms the comparison methods on five datasets of ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50, UCF_QNRF and JHU-CROWD++.
I.INTRODUCTION
WITH the increase of the global population and human social activities, large crowds often gather in public places, which brings huge hidden dangers to public safety.Therefore, determining how to accurately estimate crowd density has become an important research topic in the field of public safety.To train a robust and reliable network for accurate crowd density estimation, most existing crowd density estimation networks use a fully-supervised or semi-supervised training method, the network model is trained through the ground truth generated by manual annotation, which requires a lot of manpower, material and financial resources,and in large-scale dense crowd images, interference factors such as low resolution, object occlusion, and scale changes make it difficult to label each pedestrian in the crowd.Therefore, determining how to trade off the accuracy of crowd density estimation and dataset labeling cost, and save the dataset labeling cost without losing counting accuracy becomes a challenge.
The crowd density estimation method mainly obtains the number of crowds by extracting crowd information from the image.Existing crowd density estimation training methods mainly include fully-supervised methods [1]-[25] and semisupervised methods [26]-[39].The fully-supervised method is to obtain the ground truth by manually labeling each pedestrian in the image, and then training the network model through the ground truth, although this method shows high performance in crowd density estimation, it requires significant manpower, material and financial resources to label people in the image; the ground truth for the semi-supervised method is mainly divided into two types, that is, we mark all pedestrians in some images and mark some pedestrians in all images; this method is close to the fully-supervised method in crowd density estimation and shows good robustness, but this method still needs to label crowds in the image, and the training process is very cumbersome.Moreover, the problem faced by both fully-supervised and semi supervised methods is the limitation of the dataset.Then, the method for obtaining the distribution of the crowd changes, such with a change in the shooting perspective or the spatial distribution characteristics of the crowd, the ground truth obtained under the current labeling method, needs to be re-labeled, and the labeled ground truth will not be used to evaluate the counting performance during the test process.This means that the ground truth labeled for each pedestrian is redundant.To reduce the cost of manual labeling, weakly-supervised training methods are proposed, and the main difference between these methods and the fully-supervised and semi-supervised methods are that the weakly-supervised methods do not require any manual annotation of the crowd location information at all, while the fully-supervised and semi-supervised methods require manual annotation of all or part of the crowd location information.In fact, without the demand for locations, the crowd numbers can be obtained in other economical ways.For instance, with an already collected dataset, the crowd numbers can be obtained by gathering the environmental information, e.g., detection of disturbances in spaces, or estimation of the number of moving crowds.Chanet al.[40] segment the scene by crowd motions and estimate the crowd number by calculating the area of the segmented regions.To collect a novel counting dataset, we can employ sensor technology to obtain the crowd number in constrained scenes, such as mobile crowd sensing technology [41].Moreover, Shenget al.[42] propose a GPSless energy-efficient sensing scheduling to acquire the crowd number more economically.On the other hand, several approaches [43]-[46] prove that, with the estimated results,there is no tight bond between the crowd number and the location.The weakly-supervised labeling data in this paper, all of which were obtained from already collected datasets, use only the crowd’s quantity labeling and drop the location labeling information.
However, although such weakly-supervised methods save the cost of dataset labeling, the ensuing problem is that the network does not know the characteristics of pedestrians at the beginning of the training process, due to the lack of the location information of the crowd as the training label, and the characteristics of pedestrians are learned only after several iterations, which leads to reduced sensitivity of the network to crowd features, and the convergence speed of the network becomes very slow, and the network model’s ability to fit features is substantially reduced, which affects the accuracy of crowd density estimation.Therefore, the weakly-supervised approach of simply removing the crowd location information saves the cost of labeling the dataset, but limits the performance of the network and does not fundamentally solve the problem.
To solve the above problem, inspired by the optimal iterative learning control methods [47]-[49], reaction–diffusion neural networks [50] and the model latent factor analysis[51]-[54], we reconsider the training approach of the crowd density estimation model and also sample weakly-supervised data labels, i.e., we use only the number of pedestrians in the image as supervised.However, to compensate for the missing crowd location information and to improve the convergence speed of the network and the feature fitting ability, we designed a novel and effective training method, using a parent-child network with the same parameters to learn different features in the crowd, and then using a linear transformation to correct the information location of the features extracted by the parent network using hidden features learned by the child network, to accelerate the network’s ability to adapt to the features.Our training method, significantly improves the convergence speed of the network; the network performance as well as the counting accuracy, is not much different from the fullysupervised method, and, since the parent network has the same parameters as the child network, the increment of the number of parameters of the parent-child network model is very small compared to the number of parameters of the parent network, and the increase in the number of parameters is well within the acceptable range compared to the improved performance of the network.To address the above problems,this paper designs a crowd density estimation method based weakly-supervised learning, which trains the network by correlating between global and local image features to improve the performance of the network model.The main contributions of this paper are as follows:
1) We design a weakly-supervised crowd density estimation method, which based on using only the number of crowd as supervised information without using location label supervision.It omits the manual labeling work without losing the crowd density estimation performance and greatly saves the cost of network training compared to existing fully-supervised methods.
2) We design a novel and effective training approach by designing a parent-child network, which uses incremental learning, by the characteristic linear calibration structure to enhance the adaptability of the network to hidden features using transfer factors and offset weights.It improves the performance of weakly-supervised learning methods, and we verify its effectiveness in this task.
3) We design a loss function that adds the error between the parent network features and child network features (L2) to the ground truth and predicted counting error (LC), and use gradient descent to optimize the features extracted by the parentchild network to accelerate the convergence speed of network training and improve the accuracy of crowd density estimation.
II.RELATED WORK
1)Fully-Supervised/Semi-Supervised Crowd Density Estimation Methods: With the development of big data, machine learning, and convolutional neural networks [55]-[61], a large number of convolutional neural network (CNN)-based crowd density estimation methods have been proposed.Basic CNN is first applied to crowd density estimation, such as CNNboosting [1], Wanget al.[2], these networks use basic CNN layers, including convolutional layer, pooling layer, fully connected layer, no additional feature information is required,which are simple and easy to implement, but the crowd estimation accuracy is low.Multi-column CNN is subsequently widely used, such as MCNN [3], MBTTBF [4], Multi-scale-CNN [5], CP-CNN [6], DADNet [7], these networks usually use different columns to capture multi-scale information.However the information captured by different columns is redundant and wastes many training resources.To solve the problem of redundant feature extraction by multi-column CNN, Single-column CNN is applied to crowd density estimation, such as CSRNet [8], SANet [9], SPN [10], CMSM [11],TEDnet [12], and IA-MFFCN [13].These networks usually deploy a single deeper CNN instead of the bloated structure of multi-column network architecture, do not increase the complexity of the network, and have higher training efficiency, so it has received extensive attention.However, with the development of the density map-based method, the background noise in the image seriously affects the display of the detailed information of the crowd distribution, how to filter out the background noise to highlight the crowd location information has become a challenge.
Therefore, attentional mechanisms have been widely introduced into crowd density estimation tasks, and, attentional mechanisms can supplement the features extracted by the backbone network or the head network by providing the capability to encode distant dependencies or heterogeneous interactions to highlight the head position.ADcrowdNetp designs an attention image generation structure [14], attentional neural field (ANF) uses local and global self-attention to capture long-range dependencies [15], attention guided feature pyramid network (AP-FPN) proposes an attention guided feature pyramid network [16], which adaptively combines high-level and low-level features to generate high-quality density maps with accurate spatial location information, and multi-scale feature pyramid network (MFP-Net) designs a feature pyramid fusion module using different depth and scale convolution kernels [17] where the receptive field of CNN is expanded to improve the training speed of the network, PDANet uses a feature pyramid to extract crowd features of different scales to improve counting accuracy [18], and SPN uses the scale pyramid network to effectively capture multi-scale crowd characteristics [10], and obtain more comprehensive crowd characteristic information.Meanwhile, researchers have attempted to transfer Transformer models in the field of natural language processing to the task of crowd density estimation [19]-[23],[62]-[66].Transformer uses self-attention to capture the global dependency between input and output, where the advantage is that it is not limited by local interactions, can mine long-distance dependencies and can perform parallel calculations, where the most appropriate inductive bias can be learned according to different task objectives, thereby capturing the global context information of the image and modeling the dependencies between global features, which is a good solution to the limited receptive field of CNN, especially in the presence of uneven scales in dense crowds.In 2020, Dosovitskiyet al.[19] proposed the vision transformer (ViT)model, an image classification method based entirely on the self-attention mechanism, which is also the first work of Transformer to replace convolution.In 2021, Sunet al.[24]demonstrated the importance of global contextual information in the task of crowd density estimation.In 2021, TDCrowd combines ViT and density map to estimate the number of people in the crowd [25], which solves the problem of background noise interference in crowd density estimation, and improves the accuracy of crowd density estimation.
However, the aforementioned CNN or ViT methods require a large number of labels for training, and labeling the crowd density estimation dataset is a laborious task.
2)Weakly-Supervised Crowd Density Estimation Methods:To reduce the cost of labeling the dataset, some weakly-supervised crowd density estimation methods have been developed.In the weakly-supervised methods, there is no need to label any crowd location information, and image-level count labels are used as the weakly-supervised signal for training.In 2016,Borstelet al.[37] proposed a weakly-supervised density estimation method based on the Gaussian process, using the number of objects as the label to train the network, but this method partitions the image, so that different partitions will repeat the same target, causing the estimated number of targets to be higher than the actual number.In 2019, Maet al.[38] proposed a weakly-supervised density estimation method using Bayesian loss, which performs expectation calculation from the probability density map estimated from the network, and regresses to estimate the number of people in the crowd,which improves the counting efficiency under the weaklysupervised method.In 2019, Samet al.[36], designed an autoencoder to train the network in a weakly-supervised way,updating only a small number of parameters during training,in an attempt to achieve a nearly un-supervised method for crowd density estimation.In 2020, Yanget al.[39], proposed a network based on soft label ranking, which highlights the supervision of crowd size based on the original crowd density estimation network.In 2020, Samet al.[29], by matching statistics of the distribution of labels, proposed a weaklysupervised training method that does not use image-level location labeling information.To ease the overfitting problem, in 2019, Wanget al.[27] explores the generation of synthetic crowd images to reduce the burden of annotation and alleviate overfitting.With the application of ViT in the field of crowd density estimation, in 2021, TransCrowd applied ViT to crowd density estimation for the first time [21], and proposed a weakly-supervised counting method, which greatly improved the accuracy of crowd density estimation in the weakly-supervised mode, but was affected by the simple structure of the model, where extraction of features was limited.
Compared with previous weakly-supervised methods, we proposed a weakly-supervised method based on linear calibration of parent-child network features, which can effectively reduce labeling cost during training, while maintaining stateof-the-art performance, achieving an optimal trade-off between crowd density estimation accuracy and dataset labeling cost.
III.PROPOSED METHOD
A. Overview of the Network Architecture
To improve the convergence speed of the network under the weakly-supervised training method, we propose a parent-child network (PC-Net).It exploits the correlation between global and local features in images to enhance the network’s ability to fit the features by incrementally learning and continuously linearly correcting the features extracted by the network.The proposed PC-Net structure is shown in Fig.1.The PC-Net achieves a better balance between accuracy and training costs.Specifically, PC-Net is divided into two parts, the Parent network and Child network, which have the same backbone network.We design a pyramid vision transformer as the feature extraction backbone network to extract crowd features at different levels.In the process of network training, the Parent network learns crowd features through global images, while the Child network learns feature transfer factors and feature bias weights from local images.Then, the crowd features learned by the Parent network are corrected by a linear correction structure to obtain a feature map that contains richer and more accurate global contextual information.Meanwhile, during the training of the network, the Parent and Child networks are updated with the learned weights by gradient descent using different losses to improve the accuracy of the crowd density estimation.Finally, a 1 × 1 convolutional layer is used to output the final density map.In the following sections, we describe our framework in detail.
B. Backbone Network
In PC-Net, the subject network is divided into two parts,Parent-Net and Child-Net.In order to use incremental learning, linearly correcting the crowd features, Parent-Net and Child-Net have the same network structure.In order to adapt to the problem of scale variability existing in crowd images, a pyramid vision transformer feature extraction backbone network is designed in this paper to extract crowd features at different levels, as shown in Fig.1, while using a multi-scale window to restrict the calculation of the vision transformer’s self-attention mechanism to non-overlapping local regions,which improves computational efficiency.Since the vision transformer can not directly process 2D images, an image preprocessing process is required to convert 2D images into 1D image block sequences before the images are input to pyramid vision transformer.The process of image preprocessing and the structure of the pyramid vision transformer are shown as follows.
1) Image Partition
Before the image is input into the pyramid vision transformer, the 2D image is converted into a 1D image block sequence.To improve the computational efficiency, the input image is divided intoN×Nfixed windows, and the image in the window is divided into image blocks of fixed size, and the self-attention calculation is performed in each window, as shown in Fig.2.

2)Pyramid Vision Transformer
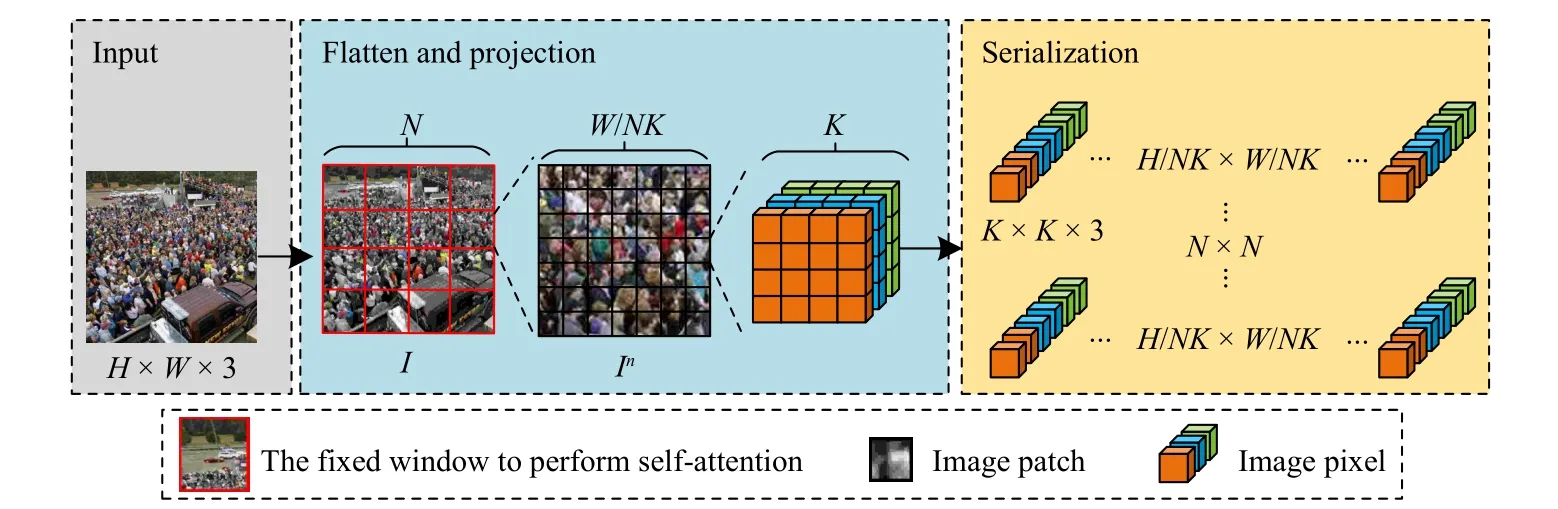
Fig.2.The process of the image partition.
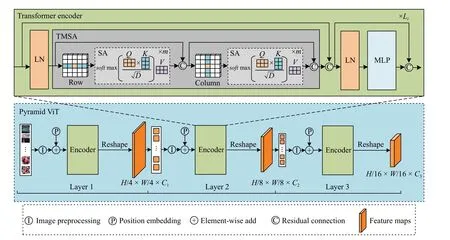
Fig.3.The structure of pyramid vision transformer.The feature map of each layer needs to be partitioned first to convert the 2D image into a 1D sequence,and then perform feature reshape on the processed 1D sequence to generate 2D features.
When extracting multi-scale crowd features, a multi-layer pyramid vision transformer structure is used.Between layers,the scale of the feature map is controlled by a strategy of progressive shrinkage.Simultaneously, the scheme using multiscale windows restricts the self-attention calculation process to non-overlapping local windows, and expands the window layer by layer through cross-window connections, which improves the computational efficiency.The method in this paper designs a three-layer transformer-encoder structure, as shown in Fig.3.
Specifically, the size of the input image isH×W× 3, the size of the output feature mapFiafter LayeriisHi×Wi×Ci,and the size of the image patch in LayeriisKi×Ki× 3, whereK1= 4,K2= 2,K3= 2, the number of Layeriwindows isNi×Ni, whereN1= 4,N2= 2,N3= 1, each window of Layericontainsimages patch, and linearly project the image patch into a 1D sequence and embed position information,after the transformer-encoder extracts features, visualize feature sequence rearrangement as feature maps, whereCiis less thanCi-1.The transformer-encoder of LayeriincludesLilayers twin multi-head attention mechanism (TMSA) and multilayer perceptron (MLP), whereL1= 2,L2= 6,L3= 2, and each layer is processed by layer normalization (LN) and residual connection.Before TMSA and MLP, LN is used to normalize the feature sequence, which makes the training process more stable and effectively avoids the problem of gradient disappearance or gradient explosion.And residual connection is used after TMSA and MLP, and the features processed by TMSA and MLP are superimposed with the features before processing to avoid the degradation problem of matrix weights in the network.The calculation process is as follows:
MSA containsmself-attention (SA) modules.In each independent SA, input sequence, calculate the query (Q), key(K) and value (V) of the sequence, where the process is as follows:
In the formula,WQ,K,Vare learnable matrices, and the outputs ofmself-attention modules are connected in series,which can be expressed as
MLP contains two linear layers with the Gaussian error linear unit (GELU) activation function.This paper uses the GELU activation function of a standard normal distribution,as shown in (8)
The first linear layer expands the dimension of the feature sequence from D to 4D, and the second linear layer shrinks the dimension of the feature sequence from 4D to D.
C. Linear Feature Calibration
In order to improve the convergence speed and feature fitting ability of the weakly-supervised crowd counting method during training, we propose a linear feature calibration structure.To achieve feature calibration and transfer between Parent-Net and Child-Net, we consider that the feature parameters of Parent-Net and Child-Net belong to the same linear spaceVn(nrepresents the number of channels of features).Each channel feature in the Child-Net can be transferred from the corresponding channel feature in the Parent-Net by a linear transformation.Fig.4 shows how the Child-Net feature’s parameters are transferred from the Parent-Net by a linear calibration.
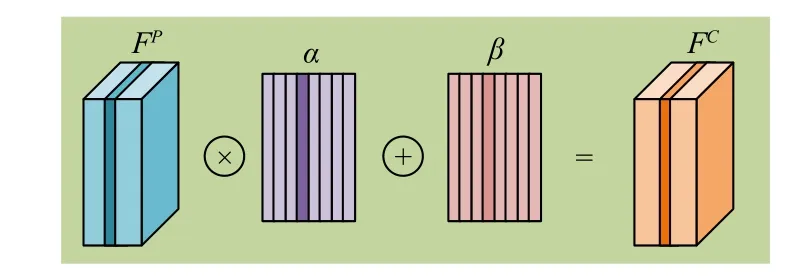
Fig.4.The process of the linear feature calibration.
InFig.4, wedefinethechannelfeaturesinParent-NetasFP∈Rh×w×n(h,w,nrepresentthelength,width,andnumber of channels of the features, respectively), the feature transfer factors as α ∈R1×1×n, and the feature bias weights as β ∈R1×1×n, so the process of linear feature correction can be expressed as
D. Loss Function
In order to further strengthen the method proposed in this paper, we make full use of the correlation between the local and global crowd feature information to train the network, and improve the accuracy of crowd density estimation.The comprehensive loss function is designed, which consists ofLCloss function andL2loss function, as shown in (10)
In the formula,LCis the counting loss of the PC-Net estimated number of people with the ground truth, andL2is the MSE loss between PC-Net predicted density map and parentnet predicted density map, where, theLCcounting loss can be expressed as
In the formula,Ndenotes the number of images in the training set,FY(Xi,θ) denotes the estimated number of people obtained from theXi(i=1,...,N) images, andθdenotes a set of parameters that can be learned;Yidenotes the true number of people in theXi(i=1,...,N) images.L2loss can be expressed as
In the formula,Ndenotes the number of images in the training set,Xirepresents theith image of the input,θdenotes a set of parameters that can be learned, andZ(Xi,θ) denotes the prediction result of PC-Net andZP(Xi,θ) denotes the prediction result of Parent-Net.
E. Crowd Density Map Generation
The crowd features extracted by PC-Net contains the location information of each pedestrian.We use a focal inverse distance transform (FIDT) to process the features to generate a visualized crowd density map [67].The specific process can be expressed as follows: if there areZpedestrian feature points in an image, the following processing is performed on the feature images:
In (13),Zdenotes the set of all crowd feature points, and for any feature point (x,y), the Euclidean distanceP(x,y) is calculated with its nearest feature point (x′,y′).Since the distance between feature points varies greatly, it is difficult to perform distance regression directly, so the inverse function is used for regression, as shown in (14), whereIis the processing result of FIDT,Cis an additional constant, usually set to 1, to avoid division by 0 in the calculation process, andP(x,y) is exponentially processed to slow down the decay of the crowd head information, andIis visually displayed to generate a visual crowd density map.Finally, the predicted crowd density values are obtained by 2D integrating and summing the generated density maps.In the experiments,A= 0.02,B= 0.75 were set.
IV.EXPERIMENTS
A. Training Process
In the training phase, one iteration updates parameters for two models.As shown in Fig.1, first, the data are fed into Parent-Net for training, and the global featureFPis optimized using the gradient descent method, as follows:
In the formula, εdenotes the learning rate of Parent-Net, andLCis the count loss of the Parent-Net estimated number of crowd with Ground Truth.Second, we use the Linear Feature Calibration structure to transferFPchannel-by-channel into Child-Net to obtainFC, the process of transfer, as shown in(9).Since the transfer factorαand the bias weightβused in linear feature calibration need to be learned by Child-Net, we need to feed the local image data into Child-Net and optimizeFCwith the gradient descent method, as follows:
In the formula, μdenotes the learning rate of Child-Net.Loos is the value of the integrated loss function designed in this paper.In the testing phase, we use the best-performing model on the test set to make an inference.
B. Training Hyper-Parameter Settings
During training we use the Adam optimizer, Batch_size is set to 16, the learning rate εin the Parent-Net and μ in the Child-Net are initialized as 0.0001, reduced by 0.5 times after every 50 epochs, where the GELU function is used as an activation function to improve the training speed and effectively avoid the disappearance and explosion of the gradient.We use l2 regularization of 0.0001 to avoid over-fitting.Since the images in the dataset have different resolutions, the resolution of all images is adjusted to 768 × 768.The experimental environment is shown in Table I.

TABLE I EXPERIMENTAL ENVIRONMENT (TABLE I INTRODUCES THE EXPERIMENTAL ENVIRONMENT PARAMETERS FROM THE ASPECTS OF SYSTEM, FRAME, LANGUAGE, CPU, GPU AND RAM)
C. Datasets
In this work, extensive experiments are conducted on five crowd datasets of ShanghaiTech Part A, ShanghaiTech Part B,UCF_CC_50, UCF_QNRF and JHU-CROWD++.Unlike fully-supervised methods, only count-level labels are used as supervision information in the training process.Choose a representative crowd image on each dataset, as shown in Fig.5.The crowd images in each dataset have different degrees of uneven crowd scale variation.
1)ShanghaiTech[3]: It has 1198 crowd images with a total of 330165 people.The dataset contains two parts, A and B.Part A includes 482 highly crowded crowd images, of which 300 form the training dataset and the remaining 182 form the testing dataset; Part B includes 716 relatively sparse crowd images, of which 400 images form the training dataset, and the remaining 316 images form the testing dataset.
2)UCF_CC_50[68]: It has 50 crowd images, these images have different resolutions and different viewing angles.The number of pedestrians per crowd image varies from 94 to 4543, with an average of 1280 pedestrians per image.Due to the limited number of images in this dataset and the large span of the number of people in the image, five-fold cross-validation is used in this dataset.
3)UCF_QNRF[69]: It has 1535 crowd images with a total of 12 500 people, of which 1201 form the training sample set and the remaining 334 form the test sample set.The number of pedestrians per crowd image varies from 49 to 12 865, with an average of 815 pedestrians per image.

Fig.5.Crowd images from five crowd datasets.(a) From the ShanghaiTech Part A dataset; (b) From the ShanghaiTech Part B dataset; (c) From the UCF_CC_50 dataset; (d) From the UCF_QNRF dataset; (e) JHUCROWD++ dataset.
4)JHU-CROWD++[70]: It is an unconstrained dataset with 4372 images that are collected under various weatherbased conditions such as rain, snow, etc.and contains 2722 training images, 500 validation images, and 1600 testing images.This dataset contains 1.5 million annotations at both image level and head-level.The total number of people in each image ranges from 0 to 25 791.
D. Evaluation Metric
In this paper, we use mean absolute error (MAE), mean squared error (MSE), and mean absolute percentage error(MAPE) as evaluation metrics for PC-Net performance.MAE is the average absolute value of the difference between the target and estimated densities, and it is the averageL1loss between the target and estimated densities.It can highlight outliers in the data, and its value is not affected by the influence of outliers, making it more robust in evaluating algorithm performance.MSE is the average squared value of the difference between the target density and the estimated density, and it is the averageL2loss between the target density and the estimated density, which can penalize larger error values.MSE usually magnifies the effect of squared error to make it easier to distinguish between models with larger error values.MAPE is a measure of the relative error between the estimated and actual values, which makes it easier to compare the variability of algorithms on different datasets, and it uses the percentage error to measure the prediction error, which is more convenient in practice, more intuitive, easy to explain.MAPE can avoid the problem of “mean squared error inflation” that tends to occur in MSE, i.e., when there are outlier values in the dataset, as the impact on MAPE is smaller.In summary, the three metrics MAE, MSE, and MAPE are chosen to evaluate the algorithm in this paper, which can well demonstrate the robustness as well as the accuracy of PC-Net.The calculation is shown as follows:
Intheformula,Nrepresentsthenumberoftestimages,Cirepresentstheactualnumberofpeopleintheith image,andC?irepresents the estimated number of people in theith image.When the values of MAE, MSE and MAPE are smaller, the error between the estimated number of people and the actual number of people is smaller, indicating that the effect of the experiment is better.
E. Experiment 1: Comparisons With State-of-the-Art Methods
The ShanghaiTech dataset is a crowded and multi-scale dataset, to verify the counting performance of PC-Net.Experiments are performed on this dataset and compared with stateof-the-art methods, and the results of MAE, MSE and MAPE are given in Table II.The UCF_CC_50 dataset includes 50 grayscale images, where the images have different resolutions and viewing angles, which is a very challenging dataset with various crowd scenes and a limited total number of images;Therefore, five-fold cross-validation is performed to maximize the use of samples, and the dataset is randomly divided into 5 equal parts.Each part contains 10 images, four of which are used as the training dataset, and the remaining one is used as the testing dataset, where a total of five trainings and testings are performed.Finally the average value of the error index is taken as the final experimental result, and compared with state-of-the-art methods.The results of MAE, MSE and MAPE are given in Table II.UCF_QNRF dataset is also a crowded and multi-scale dataset, which is collected from three different datasets and includes various scenes around the world.The total number of images and the total number of people far exceed the first three datasets, and compared with state-of-the-art methods, the results of MAE, MSE and MAPE are given in Table II.JUU-CROWD++ is a super large dataset, which contains crowd images under various complex weather conditions.Compared with state-of-the-art methods,the results of MAE, MSE and MAPE are given in Table II.
1)Performance on the ShanghaiTech Dataset: In this paper,PC-Net is compared with state-of-the-art methods, and the results are show shown in Table II, where we divide these methods into two groups.The first group is the fully-supervised methods, which uses location information and population number information as supervised information.The second group is the weakly-supervised methods, which uses only population number information as supervised information.According to Table II, PC-Net is very competitive with the first group.Although MAE, MSE, and MAPE do not achieve the optimal results, they are more advantageous than most of the fully-supervised methods such as GL, LW-Count, etc.,PC-Net largely closes the gap in counting performance between weakly-supervised methods and fully-supervised methods, and its labeling cost is much lower than that of fullysupervised methods.The advantage of PC-Net over the second group is more obvious, as MAE, MSE and MAPE are better than the existing weakly-supervised methods.On Part A,MAE, MSE and MAPE are improved by 11.2%, 14.8% and 12.5%, respectively, and on Part B, MAE, MSE and MAPE are improved by 21.5%, 35.4% and 22.2%, respectively.Thus,it is demonstrated that PC-Net can achieve the best density estimation performance with a weakly-supervised training mode by training with feature linear correction.Figs.6(a) and 6(b) shows some visualization results of PC-Net on Part A and Part B datasets.
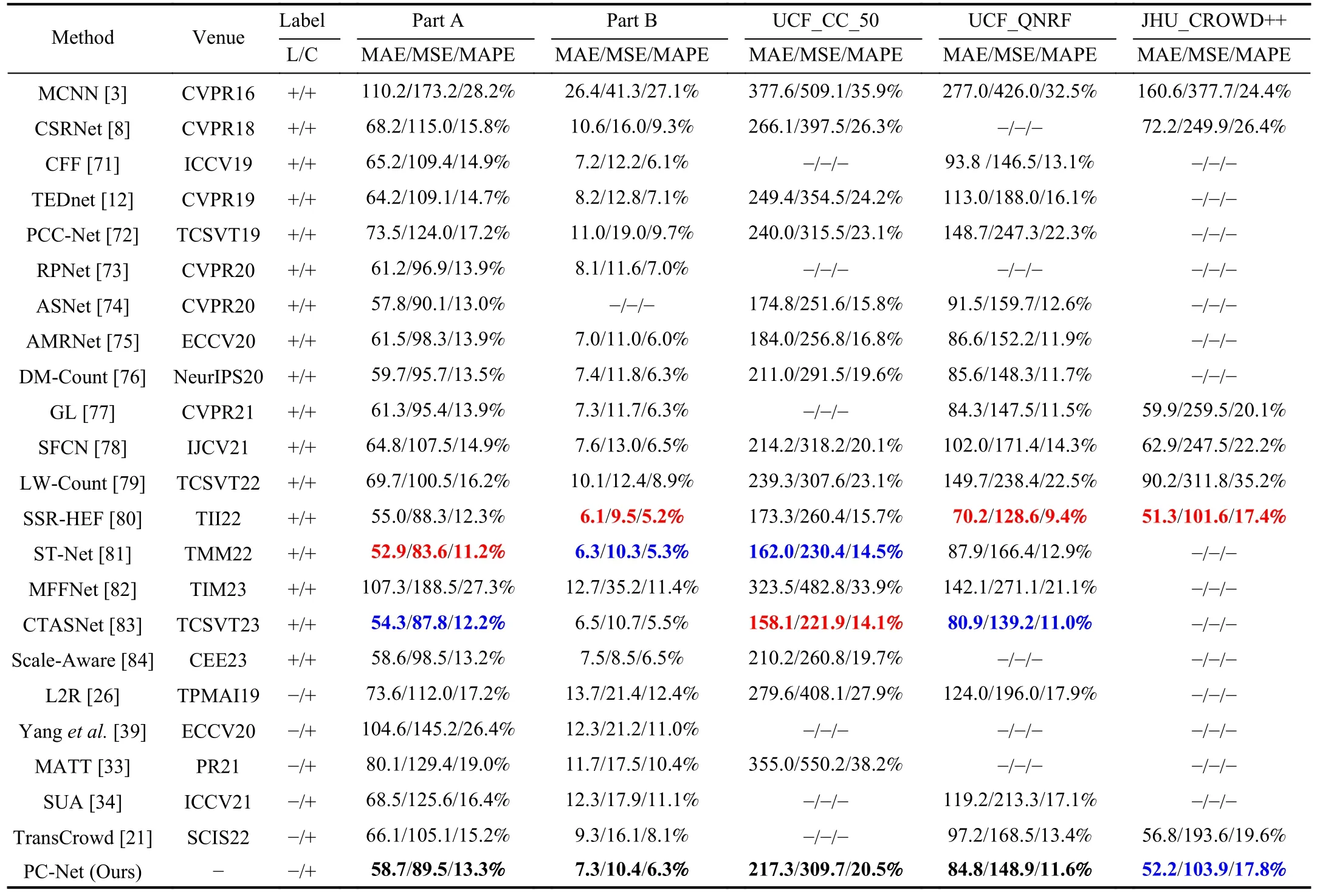
TABLE II COMPARISON OF PC-NET AND THE STATE-OF-THE-ART METHODS ON THE SHANGHAITECH, UCF_CC_50, UCF-QNRF AND JHU_CROWD++ DATASETS.L DENOTES THE TRAINING LABEL CONTAINS LOCATION INFORMATION, AND C DENOTES THE TRAINING LABEL CONTAINS POPULATION NUMBER INFORMATION.RED AND BLUE INDICATE THE FIRST AND THE SECOND-BEST PERFORMANCES, RESPECTIVELY
It can be seen that PC-Net performs well on two datasets,generating accurately distributed density maps with high resolution, and the prediction results are close to the true values.Comparing Figs.6(a) and 6(b), the ShanghaiTech Part A dataset is extremely crowded and has little change in crowd scale, while the ShanghaiTech Part B dataset is relatively sparse but has large change in crowd scale, which indicates that PC-Net can be a good fit for different degrees of crowd scale changes.The third column of Fig.6, gives the heat map of the Parent-Net output, and we use the red box to mark out the obvious misidentification or omission of identification.It can be seen that extracting the crowd features using only Parent-Net can easily produce misidentification of crowd features.The process of crowd feature correction and transfer, on the other hand, corrects the location information of the crowd well, which further compensates for the lack of crowd location information under the weakly-supervised crowd counting method and further improves the accuracy of the crowd counting.
2)Performance on the UCF_CC_50 Dataset: According to Table II, under the weakly-supervised training, compared to the second group, PC-Net outperforms other weakly-supervised methods on the UCF_CC_50 dataset, with MAE, MSE and MAPE improving by 38.8%, 43.7% and 46.3%, respectively, which proves the superiority of PC-Net.However,compared with the first group, PC-Net has obvious shortcomings, probably because the data in this dataset is limited and the number of people included in the images spans a relatively large range.The prediction results are not stable enough, and there are a small number of images with large errors, which leads to a decrease in the performance of the method.Fig.7 shows some visualization results of PC-Net on UCF_CC_50 dataset.
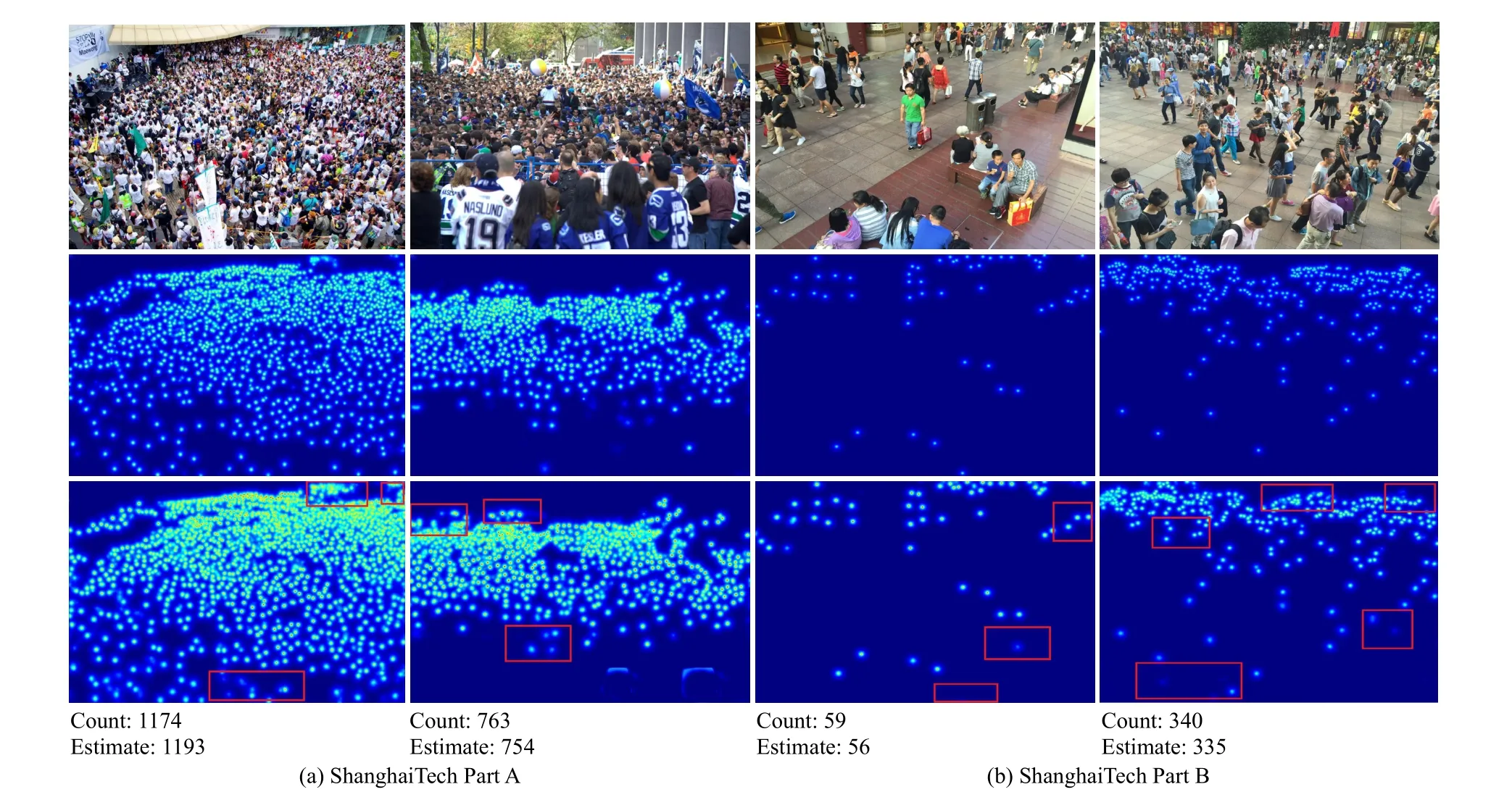
Fig.6.Visualization results of the density maps on (a) ShanghaiTech Part A and (b) ShanghaiTech Part B, respectively.
In the second column of Fig.7, the crowd density map generated by PC-Net is given, it can be seen that PC-Net can make good predictions and generate accurate density maps in crowded scenarios with variable scales, and the generated density maps have different sparsity for different scales of crowds, but the estimated values have some errors relative to the real values, such as the first set of images, which are a small number of images with large errors in the test of this paper.It is possible that the low brightness of the image is affecting the counting performance of the network.To further evaluate the visualized crowd density images, we manually label several samples containing crowd locations and perform a visual display of crowd locations, as shown in the third column of Fig.7.A new set of evaluation metrics, structural similarity (SSIM) and peak signal-to-noise ratio (PSNR), were also used to evaluate the generated crowd density maps with labeled density maps, which compensate for the shortcomings of the one-dimensional evaluation metrics such as MAE and MSE.The experimental results show that PC-Net can fit the location information of the crowd well, and although there are some location errors, they are within the acceptable range.To summarize, PC-Net’s counting performance is slightly insufficient in the face of extremely crowded crowds, so more data is needed for training to improve the accuracy of the model on extremely crowded datasets.

Fig.7.Visualization results of the density maps on UCF_CC_50.
3)Performance on the UCF_QNRF Dataset: According to Table II, compared with the second group of methods, in the weakly-supervised mode, the MAE, MSE and MAPE of PCNet improved by 12.8%, 11.6% and 13.4%, respectively,which indicates a significant improvement in the prediction effect.PC-Net achieved optimal counting accuracy on this dataset and showed excellent robustness.Compared with the first group of methods, PC-Net also outperforms some of the fully-supervised training methods, such as L2R and TEDnet,etc., further narrowing the gap in counting performance between weakly-supervised training methods and fully-supervised training methods, and comparing some of the most advanced crowd density estimation methods, PC-Net greatly reduces the injection cost of the dataset label, although its performance is slightly worse.Fig.8 shows some visualization results of PC-Net on the UCF_QNRF dataset.

Fig.8.Visualization results of the density maps on UCF_QNRF.
It can be seen that PC-Net has a good ability to fit the crowd of different scales in the first image of Fig.8, and generates an accurate and high resolution density map, which reflects that PC-Net has a good ability to solve the problem of drastic changes in the scale of the crowd.PC-Net also generates an accurate density map for the denser crowd in the second image, but there is a certain error in the estimated value relative to the real value, which is a small number of images with large errors in the test of this paper’s method, probably because the difference in lighting interferes with the counting accuracy, and more training is needed in the next step to improve the robustness of the model and exclude large errors.
4)Performance on the JHU-CROWD++Dataset: According to Table II, PC-Net has a great advantage over both the first and second group of methods, and it is superior to the weakly-supervised methods, such as the advanced method TransCrowd.In addition, compared with fully-supervised methods, such as MCNN and CSRNet, the counting accuracy of PC-Net has been significantly improved on this dataset, and MAE, MSE and MAPE all achieved the second best performance, which proves the effectiveness of our method.Fig.9 shows some visualization results of PC-Net on JHUCROWD++ dataset, including the plots of crowd density in rainy and snowy days.It can be seen that PC-Net can better process the crowd images under the deteriorating weather conditions.
F. Experiment 2: Actual Experiment
In order to test the performance of PC-Net in practical applications, we conducted experiments in several real scenarios.To ensure the applicability and universality of the experiments, images taken by cameras on campuses, subway stations and city roads were randomly selected as test set, The test set contains a total of 400 images with more than 10 scenes, each containing a number of people ranging from 0 to 2000, all with a resolution of 768 × 768, and these data generally have uneven scales, background noise and other common factors that affect the accuracy of crowd density estimation.We conducted multiple groups of experiments and took the average value as the result of the test, and the experimental results are shown in Table III.Fig.10 shows some visualization results of actual experiment.

Fig.9.Visualization results of the density maps on JHU-CROWD++.
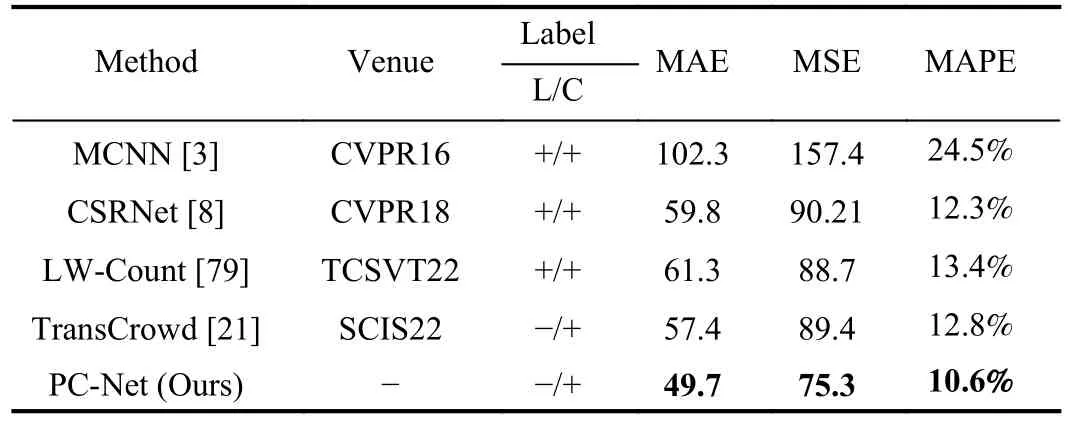
TABLE III COMPARISON OF PC-NET AND THE OTHER METHODS ON THE RANDOM DATASET

Fig.10.Visualization results of the density maps of the actual experiment.
It can be seen that the test results of PC-Net on the unfamiliar dataset still outperformed the compared algorithms, and the MAE, MSE, and MAPE all obtained the optimal results.Here we randomly selected the visualization results of four scenes, and we can see that PC-Net has some adaptability to scenes that have never been seen before, and can also generate accurate and high-resolution crowd density maps, and the predicted crowd density is within an acceptable error range compared with the real crowd density.However, the results of the multi-scene test reveal the problem where the migration of PC-Net for multiple scenes is slightly insufficient, such as the third and fourth group of images.The error of the crowd density in this scene is obviously slightly larger, and the main problem is the poor adaptability of PC-Net for this scene.Therefore, PC-Net needs to increase the training sample and test in multiple scenes to adjust its model parameters and also increase its adaptability to multiple scenes.
V.DISCUSSION
A. Study of Training Hyper-Parameter Settings
In the training process of the network, the selection of the initial training hyper-parameter is crucial to the success of the network training.Setting good parameters can help avoid gradient disappearance or gradient explosion during the network training process, and make the neural network learn the features of the data more quickly and accurately, and improve the training effect and generalization ability of the model.In order to determine the optimal initialization parameters, we discussed the effects of different Batch_size, learning rate, activation function and optimizer on the performance of PC-Net in ShanghaiTech Part A.The experimental results are shown in Fig.11.
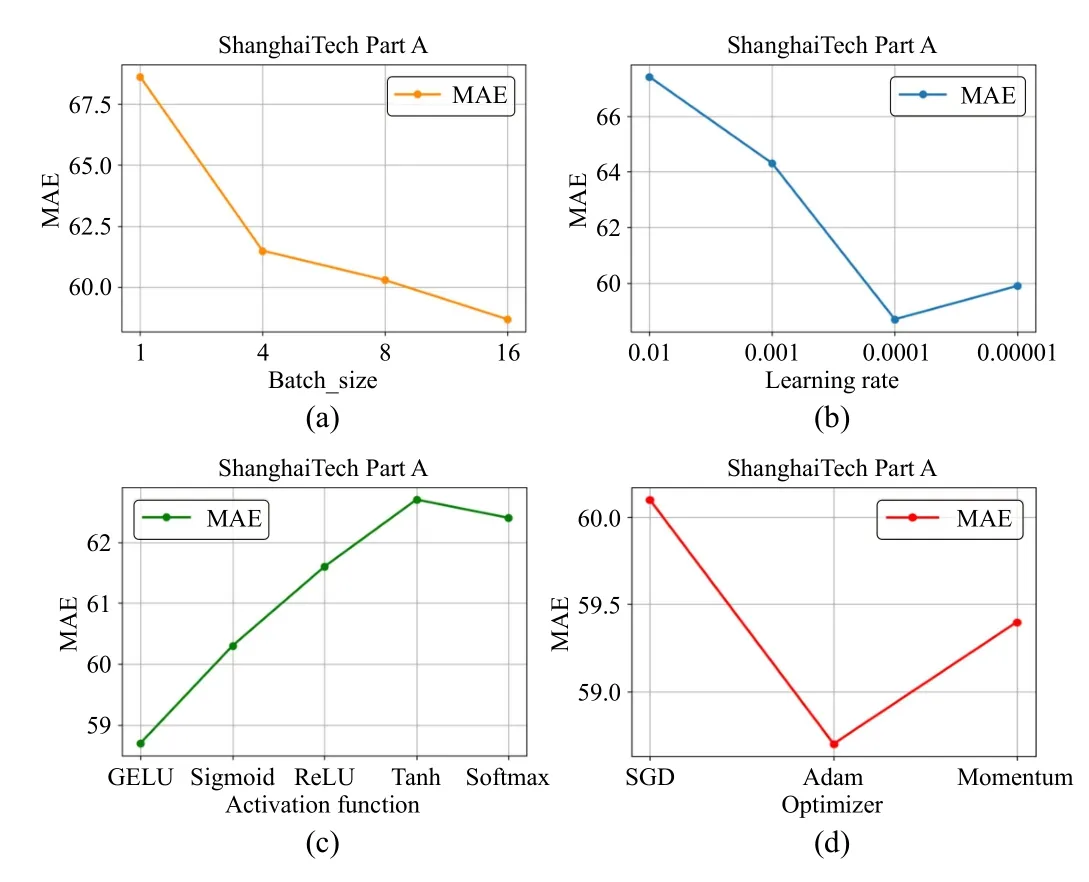
Fig.11.Visualization results of the study of different initialization hyperparameter settings.(a) Denotes the MAE values for different Batch_size; (b)Denotes the MAE values for different Learning rate; (c) Denotes the MAE values for different Activation function; (d) Denotes the MAE values for different Optimizer.
It can be seen that PC-Net is more sensitive to Batch_size and learning rate during the training process.As the Batch_size increases, the parallel performance of GPU is fully utilized, thus speeding up the training of the model.A larger Batch_size requires more memory storage, and a larger Batch_size may lead to overfitting because the model is more likely to memorize a larger Batch_size and thus fail to learn the overall features of the input data; therefore, on balance, we set the Batch_size to 16.Due to the complexity of the crowd density estimation task and the depth of PC-Net layers, we consider setting a smaller initial learning rate in order to avoid unstable or scattered training.The experimental results show that optimal model performance is achieved when the initial learning rate is set to 0.0001.For the activation function and the optimizer, the experimental results show that PC-Net is less sensitive to them.We compared five activation functions(GELU, Sigmoid, ReLU, Tanh, Softmax) and three optimizers (SGD, Adam, Momentum).The experimental results show that PC-Net achieves optimal results when GELU is used as the activation function and Adam is used as the optimizer.In summary, we set the Batch_size to 16, set the initial learning rate to 0.0001, and use GELU as the activation function and Adam optimizer at the beginning of the training.
B. Study of Backbone Network
With CNN-based deep learning, because CNNs have a small receptive field, this limits the upper limit of the global feature extraction range of the network.Therefore, CNNbased methods are more capable of extracting local crowd information in small intervals, but are not enough for global crowd information extraction of the whole image, which makes it difficult for CNN-based methods to establish global context features.However, ViT has the advantage of capturing long context dependencies and a global receptive domain,which is a good remedy for this deficiency of CNN.We calculated effective receptive fields for both VGG network and ViT.Specifically, we measure the effective receptive field of different layers as the absolute value of the gradient of the center location of the feature map with respect to the input.Results are averaged across all channels in each map for 16 randomly selected images, with results in Fig.12.
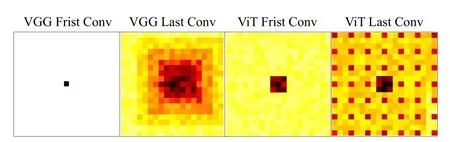
Fig.12.Visualization results of the effective receptive fields for VGG and ViT.
We observe that lower layer effective receptive fields for ViT are indeed larger than in VGG, and while VGG effective receptive fields grow gradually, ViT receptive fields become much more global midway through the network.ViT receptive fields also show strong dependence on their center patch due to their strong residual connections.Overall, VGG effective receptive fields are highly local and grow gradually, ViT effective receptive fields shift from local to global.To further verify the superiority of the performance of pyramid vision transformer, we conducted an ablation study using the first 10 layers of VGG16 replacing pyramid vision transformer as the backbone network of PC-Net, keeping the other structures the same; the results are shown in Table IV.
As can be seen, the performance of the pyramid vision transformer is significantly better than that of VGG.On the Part A dataset, MAE, MSE and MAPE are improved by 5.6%,2.2% and 6.3%, respectively.On the Part B dataset, MAE,MSE and MAPE are improved by 23.2%, 27.3% and 24.1%,respectively.On UCF_CC_50 dataset, MAE, MSE and MAPE are improved by 10.6%, 9.8% and 14.9%, respectively.On UCF_QNRF dataset, MAE, MSE and MAPE are improved by 13.8%, 11.0% and 15.3%, respectively.On the JHUCROWD++ dataset MAE, MSE and MAPE are improved by 23.7%, 26.4% and 27.6%, respectively.This is further proof of the superiority of PC-Net’s performance.

TABLE IV RESULTS OF BACKBONE NETWORK ABLATION STUDY

TABLE V RESULTS OF PYRAMID VISION TRANSFORMER ABLATION STUDY
C. Study of Pyramid Vision Transformer
The pyramid vision transformer structure proposed in this paper consists of three layers of ViT; to verify its rationality,ablation experiments were conducted on five datasets, keeping the other structures the same in the experiments to test the performance of the pyramid vision transformer under different configurations.The results are shown in Table V, where L* represents the number of layers of ViT in pyramid vision transformer.
As can be seen, the performance of PC-Net improves as the first three layers of ViT are stacked in the pyramid vision transformer, but when the ViT is stacked to the 4th layer, the performance of the model is almost the same as the 3-layer ViT, and even some metrics appear to decrease; when the number of layers of ViT continues to increase to the 5th layer,the performance of the model starts to decrease rapidly.We believe that as the depth of the network increases, the gradients in the backpropagation may become very small, leading to the gradient vanishing problem, or the gradients become very large, leading to the gradient exploding problem.These problems can make the training process difficult and make convergence impossible.Moreover, as the depth of the network increases, the number of parameters in the network increases exponentially, which can over-fit the network and make it unable to generalize to new datasets, reducing the generalization ability of the network.Therefore, we take the above factors into consideration and set the number of layers of ViT in pyramid vision transformer as 3.
D. Study of Linear Feature Calibration
In this paper, we propose a new training method using a linear feature calibration to train the network through incremental learning, which utilizes the correlation between global and local image features.To verify its effectiveness, we tested the convergence speed of the network under different supervision methods on the ShanghaiTech dataset, and the results are shown in Fig.13.
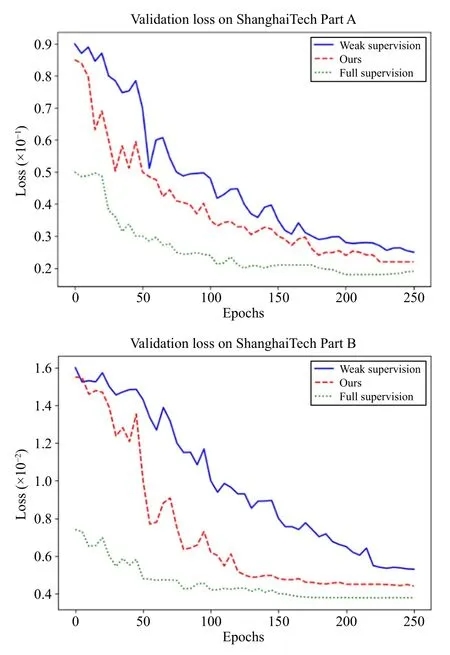
Fig.13.Convergence speed of networks under different supervision methods.The abscissa is the training Epochs, and the ordinate is the loss value during training.The three training methods sample the same backbone network,which is the backbone network proposed in this paper.
Here, the “weakly-supervised” training method means that instead of using the linear feature calibration structure proposed in this paper, a channel attention fusion approach is used, and the features extracted from the Parent-Net and Child-Net are weighted and fused.It can be seen that the convergence speed and the fitting ability of our proposed the training method are clearly better than those of the “weaklysupervised” training method.However, it can be seen that,compared with the fully-supervised method, the convergence stability of PC-Net is poor during the training process.The reason is that during the training process, there is uncertainty in the sample labels, which increases the learning difficulty of the model, and the model may be affected by noise and learn the wrong features, resulting in overfitting or under fitting,causing the model to converge unstably.We believe that we can try to use a nonlinear feature correction process to increase the stability of the training process.
E. Study of Loss function
The loss function is very important in the training process of the network, and using different loss functions will have a great impact on the performance of the model regression,therefore, a comprehensive loss function is designed and the weight ofL2andLCis adjusted by loss weights.To obtain the optimal loss function, experiments are conducted on the ShanghaiTech and UCF_QNRF datasets, and the values of?is discussed.The results are shown in Fig.14.
As can be seen, different weight loss functions have an impact on the performance of the network model, and MAE and MSE change with ?, showing a trend of decreasing and then increasing, which proves the rationality of the two-part loss function.The optimal values of MAE and MSE were obtained at ?=0.6, which proved the improvement of the comprehensive loss function on the network performance.
F. Study of Network Parameters
To analyze the parameter complexity and time complexity of PC-Net, we compared MAE, Params, and inference time on the ShanghaiTech dataset, and the experimental results are shown in Table VI.
As can be seen, the advantage of PC-Net is that it uses a weakly-supervised training method, which reduces the training cost; the MAE as well as the density estimation performance is good, however, the number of parameters is slightly larger and the required inference time is longer.Therefore, the performance of PC-Net suffers and the density estimation accuracy decreases when applied to devices with limited computational resources, such as embedded devices.Therefore, in future work, we consider studying a lightweight method based on PC-Net to analyze the parameter bottleneck layer in PCNet, find the part of the network that consumes the most time and computational resources, and compress it to improve the training and application of the network.
VI.CONCLUSION AND FUTURE WORK
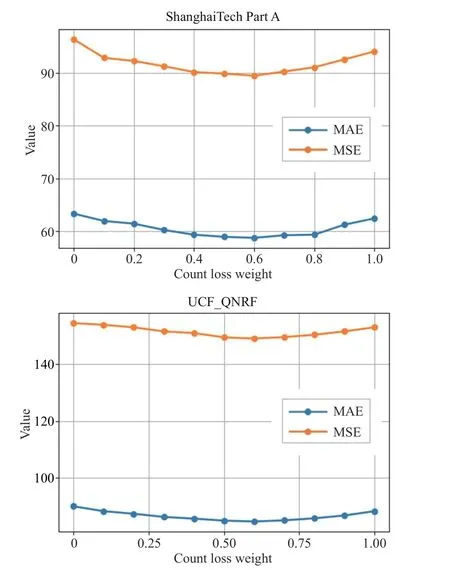
Fig.14.MAE and MSE in ShanghaiTech Part A and UCF_QNRF datasets under different counting loss weights.
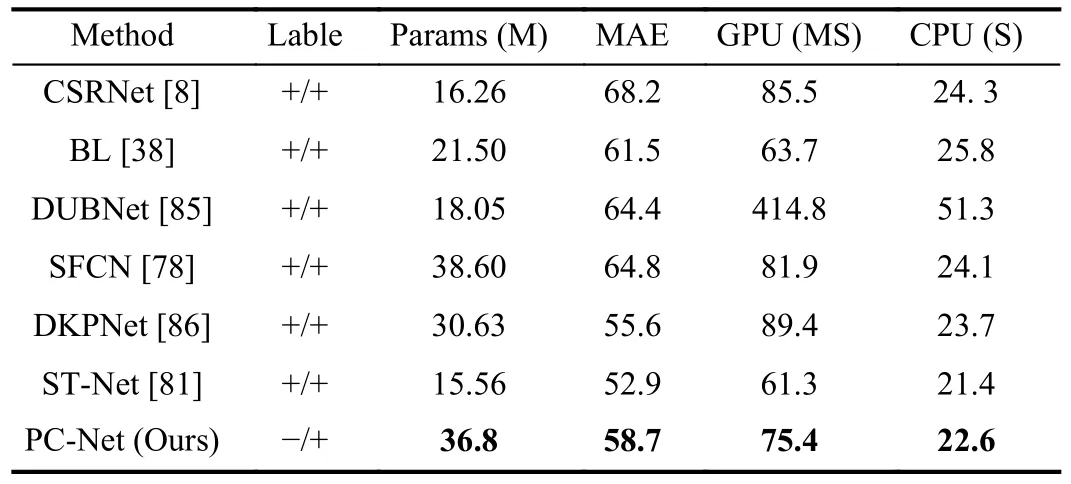
TABLE VI VI COMPARISON OF THE PARAMS, MAE AND RUNNING TIME OF PC-NET AND OTHER METHODS ON THE SHANGHAITECH DATASET
In this paper, an effective weakly-supervised crowd density estimation method is proposed and a novel training method is used to achieve an optimal balance between training costs and counting performance.The network mainly consists of a pair of parent-child networks and a linear feature calibration structure.Specifically, the parent network is used to extract the crowd features, the child network is used to extract the feature correction parameters and bias weights, and the features are calibrated using the linear feature calibration structure to improve the convergence speed as well as the fitting ability of the network.In addition, a pyramid vision transformer is used as the backbone network of the PC-Net to solve the problem of uneven scale in the crowd, while the spatial correlation and crowd sensitivity of density map are enhanced by global-local feature loss and counting loss.
In future work, we will study a crowd counting and positioning method based on PC-Net, which can not only achieve a better personal positioning function and counting accuracy,but also the number of parameters is smaller and more stable during training.
 IEEE/CAA Journal of Automatica Sinica2024年4期
IEEE/CAA Journal of Automatica Sinica2024年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Parameter-Free Shifted Laplacian Reconstruction for Multiple Kernel Clustering
- A Novel Trajectory Tracking Control of AGV Based on Udwadia-Kalaba Approach
- Attack-Resilient Distributed Cooperative Control of Virtually Coupled High-Speed Trains via Topology Reconfiguration
- Synchronization of Drive-Response Networks With Delays on Time Scales
- Policy Gradient Adaptive Dynamic Programming for Model-Free Multi-Objective Optimal Control
- Lyapunov Conditions for Finite-Time Input-to-State Stability of Impulsive Switched Systems