
Policy Gradient Adaptive Dynamic Programming for Model-Free Multi-Objective Optimal Control
2024-04-15 09:37:48HaoZhangYanLiZhupingWangYiDingandHuaichengYan
Hao Zhang , Yan Li , Zhuping Wang , Yi Ding , and Huaicheng Yan
Dear Editor,
In this letter, the multi-objective optimal control problem of nonlinear discrete-time systems is investigated.A data-driven policy gradient algorithm is proposed in which the action-state value function is used to evaluate the policy.In the policy improvement process, the policy gradient based method is employed, which can improve the performance of the system and finally derive the optimal policy in the Pareto sense.The actor-critic structure is established to implement the algorithm.In order to improve the efficiency of data usage and enhance the learning effect, the experience replay technology is used during the training process, with both offline data and online data.Finally, simulation is given to illustrate the effectiveness of the method.
Introduction: The multi-objective optimal control problems have become a growing research field in recent years, due to its wide application in autonomous driving [1], smart grid [2] and other autonomous intelligent systems [3].In some cases, the multi-objective optimal control problems can be converted to solve the Hamilton-Jacobi-Bellman equation (HJBE), which need accurate system model parameters.However, it is hard to find optimal controllers for systems without accurate models.At present, reinforcement learning as a model-free multi-objective optimal control method, which is widely used to learn policy from the process that interacts with the unknown environment.
In recent years, ADP is introduced in order to solve the problem that HJBE cannot solve directly.The generalized policy iteration algorithm was proposed by combining the policy iteration algorithm with the value iteration [4].Under the framework of policy iterative algorithm, the policy gradient adaptive dynamic programming(PGADP) is an important policy-based method.It used the gradient descent in step of policy improvement [5].In [6], the experience replay was used in combination with ADP, using the past and current data concurrently.In [7]–[9], the adaptive optimal controller was designed by the online actor-critic learning, in order to solve the robust optimal control problem for a class of nonlinear systems.In[10], a model-freeλ-policy iteration (λ-PI) was presented for the discrete-time linear quadratic regulation (LQR) problem.However, the above results only consider the solution under a single goal.In engineering practice and scientific research, many problems need more performance indices to describe the goals of the system.In [11], the policy iteration algorithm was extended to solve dynamic multiobjective optimal control problem for continuous-time systems.There are few results using policy gradient based methods with experience replay mechanism to solve multi-objective optimal control problems.It inspires the motivation to extend the related methods from single objective optimal control to multi-objective optimal control.
Thus, the objective of this letter is try to find the optimal controller in the sense of Pareto for a discrete-time system with multiple control objectives.The contributions of this letter can be summarized as follows.Firstly, the action-state value functionQinstead of the state value function is used in multi-objective optimal control.The potential dynamic constraints can be separated from the actual controller parameters by using the action state value function.Secondly, the dependency on the model can be removed completely.The experience replay technique is incorporated into multi-objective optimal control problem, which improves data usage efficiency with fixedsize offline dataset and single-frame real-time data received from the environment.Third, the policy gradient method is extended from single-objective optimal control to multi-objective optimal control.This method can make the learning process smoother and reduce the amount of computation.The convergence of PGADP with multiple objectives is guaranteed in this letter.
Problem statement: First, the related concept of Pareto optimal is introduced.Definition 1(Pareto optimal):ASolutionu?issaid tobeaPareto optimal solution ifJ(u?)≤J(u)forallu∈U.J(u?)
issaidtobe Pareto optimal.
Consider the autonomous intelligent systems with following discrete-time general nonlinear form:

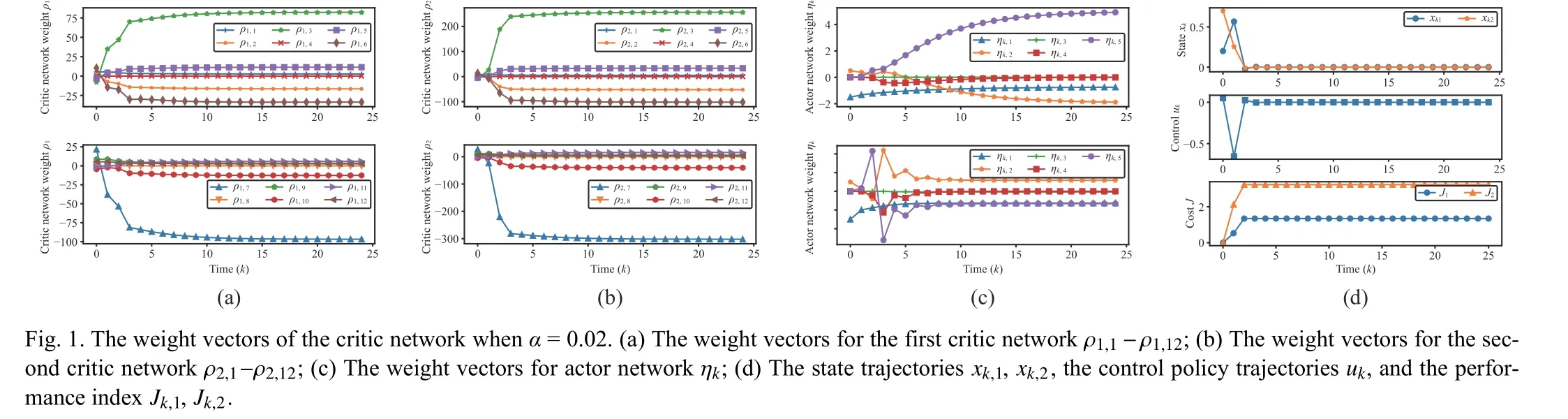
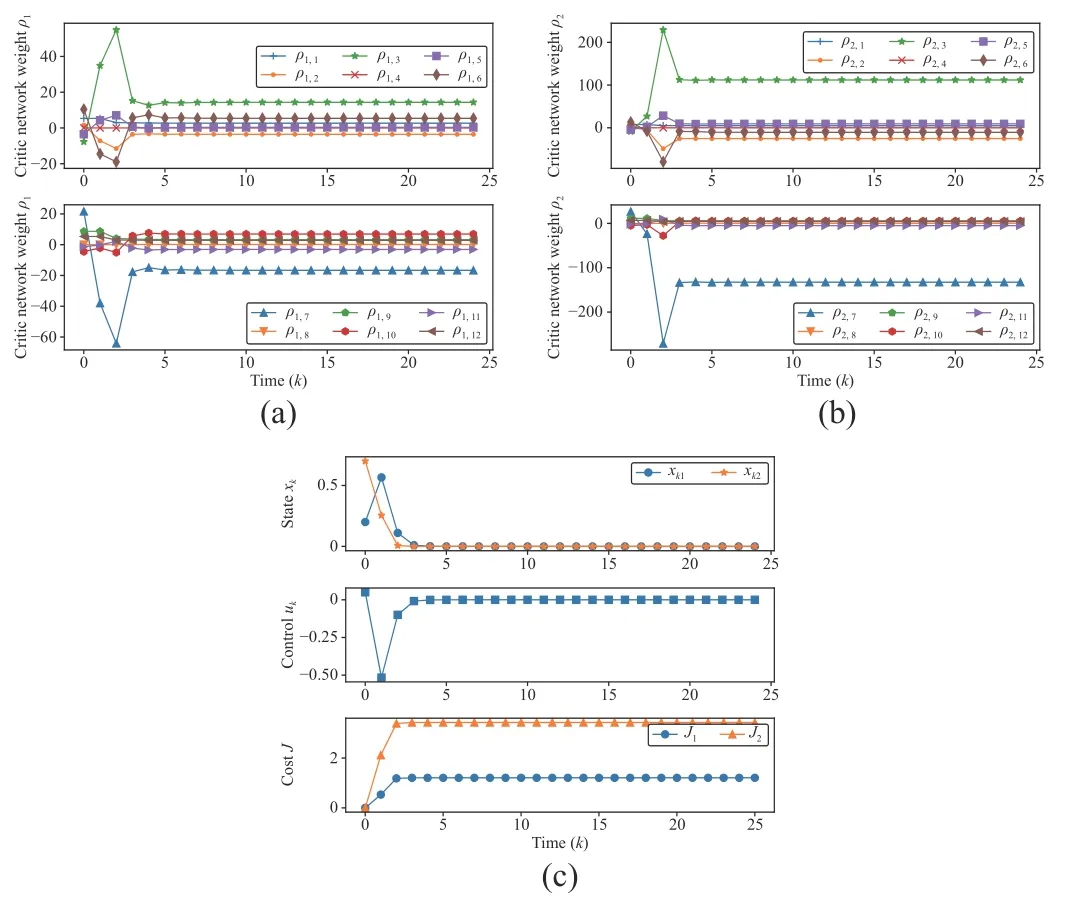
Fig.2.The weight vectors of the critic network when α = 0.06.(a) The weight vectors for the first critic network ρ 1,1-ρ1,12; (b) The weight vectors for the second critic network ρ2,1-ρ2,12 ; (c) The state trajectories xk,1 , x k,2,the control policy trajectories uk , and the performance index J k,1, J k,2.
Conclusion: In this letter, by using data from real system instead of calculating by the mathematical system models, a PGADP-based control algorithm is proposed to solve the multi-objective optimal control problem.The optimal control policy is designed to ensure the multiple objective functions converge to the optimal vectors in the Pareto sense, and the stability and convergence of the algorithm is proved.The policy gradient method is used to reduce unnecessary calculations.In addition, the experience replay technique is used to derive the rules for updating actor-critic network parameters.Finally,a simulation example is given to verify the performance of the method.The future works can be extended to the multi-objective optimization problem with conflicts and more actual situations.
Acknowledgments:This work was supported in part by the National Natural Science Foundation of China (61922063, 6227 3255, 62150026), in part by the Shanghai International Science and Technology Cooperation Project (21550760900, 22510712000), the Shanghai Municipal Science and Technology Major Project(2021SHZDZX0100), and the Fundamental Research Funds for the Central Universities.
 IEEE/CAA Journal of Automatica Sinica2024年4期
IEEE/CAA Journal of Automatica Sinica2024年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Parameter-Free Shifted Laplacian Reconstruction for Multiple Kernel Clustering
- A Novel Trajectory Tracking Control of AGV Based on Udwadia-Kalaba Approach
- Attack-Resilient Distributed Cooperative Control of Virtually Coupled High-Speed Trains via Topology Reconfiguration
- Synchronization of Drive-Response Networks With Delays on Time Scales
- Lyapunov Conditions for Finite-Time Input-to-State Stability of Impulsive Switched Systems
- Side Information-Based Stealthy False Data Injection Attacks Against Multi-Sensor Remote Estimation